第7章 Prometheus Operator
1.介绍
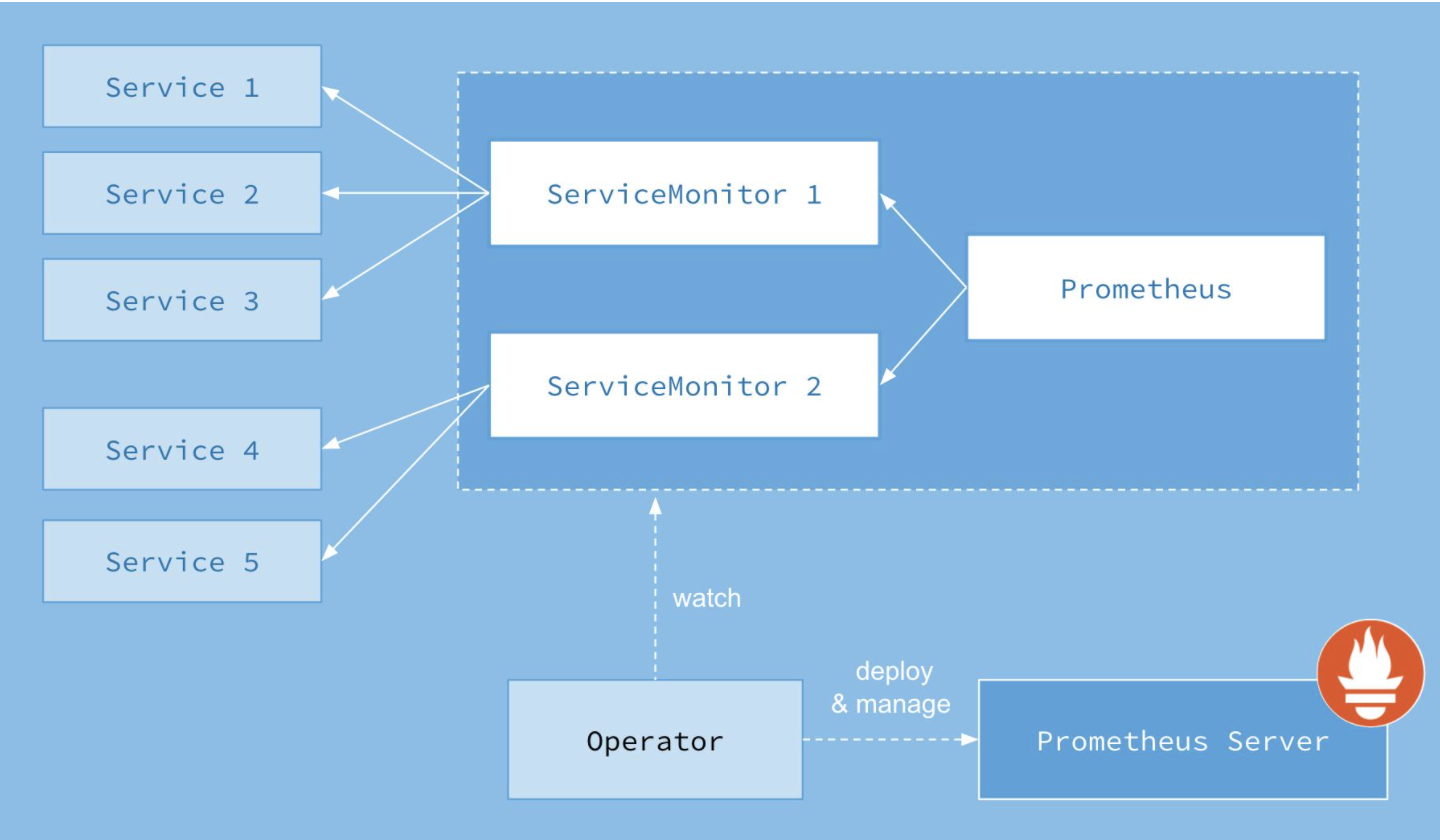
Operator:
Operator 是 Kubernetes 的一种扩展,它允许开发人员封装和自动化复杂应用的部署和生命周期管理。Operator 基于 Kubernetes 的控制器模式构建,通过自定义代码来管理特定应用或服务。它的主要作用是通过编程方式处理运行在 Kubernetes 上的服务和应用,尤其是在处理状态、配置、升级和故障恢复等方面。
Operator 通常会监听特定的资源事件,并根据预定义的业务逻辑对这些事件作出反应。例如,如果一个数据库服务需要备份,Operator 可以自动触发备份过程。这样,Operator 帮助自动化了许多原本需要手动处理的操作,使得 Kubernetes 集群的管理更加高效和可预测。
Custom Resource Definitions (CRD):
CRD 允许你在 Kubernetes 中定义新的资源类型。这些资源不是 Kubernetes 原生支持的,而是用户根据自己的需要自定义的。通过 CRD,用户可以创建专门的资源,比如数据库实例、监控配置或者任何特定的服务实例。
定义了 CRD 后,用户就可以像使用 Kubernetes 原生资源(如 Pod、Service 等)一样使用这些自定义资源。这包括通过 kubectl 命令行工具来创建、访问和管理这些资源,以及在 Kubernetes 的 API 中对其进行操作。
CRD 配合 Operator 使用时,可以非常灵活地扩展 Kubernetes 的功能。开发者可以为特定的 CRD 编写一个或多个 Operator,来自动化这些自定义资源的管理。例如,一个数据库 CRD 可以由一个数据库 Operator 管理,负责自动部署、配置、监控、备份和恢复数据库实例。
总之,Operator 和 CRD 是 Kubernetes 生态中非常强大的工具,它们使得 Kubernetes 不仅仅是一个简单的容器编排平台,更是一个可以支持复杂应用管理和自动化操作的平台。
Prometheus Operator架构:
上图是官方的架构图,其中最重要的是Operator最核心的部分,作为一个控制器,他会去创建Prometheus-Server,ServiceMonitor,AlertManager等CRD资源,然后会一直Watch监控并保持这些资源对象的状态。
最新版本包含了以下CRD资源对象:
- prometheus
- AlertManager
- ServiceMonitor
- PodMonitor
- PrometheusRule
- AlertManagerConfig
Prometheus Operator的优势:
- 简单的部署:直接集成了prometheus,grafana,alertmanager,node-exporter,kube-state-metrics等组件的所有资源配置,直接一间部署即可。
- 自动生成监控目标配置:不用像我们以前自己写自动发现的配置,现在不需要了解prometheus的配置就可以直接实现自动发现。
- 对接应用简单:现在对接应用不需要修改配置文件,只需要根据标签编写自动发现资源的清单即可。
kubectl apply -f manifests/setup
修改kube-state-metrics的镜像地址
vim manifests/kube-state-metrics-deployment.yaml
- image: bitnami/kube-state-metrics:2.1.1
创建资源
kubectl get servicemonitors --all-namespaces
kubectl apply -f manifests/
查看创建的资源
[root@node1 kube-prometheus]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 16m
alertmanager-main-1 2/2 Running 0 16m
alertmanager-main-2 2/2 Running 0 16m
blackbox-exporter-6798fb5bb4-4q55f 3/3 Running 0 16m
grafana-6ccd8d89f8-sf26x 1/1 Running 0 16m
kube-state-metrics-7fcc9c66b-bqqdm 3/3 Running 0 9s
node-exporter-4f9hz 2/2 Running 0 16m
node-exporter-64hvj 2/2 Running 0 16m
node-exporter-shv72 2/2 Running 0 16m
prometheus-adapter-5df846c94f-5hlhn 1/1 Running 0 16m
prometheus-adapter-5df846c94f-smkxs 1/1 Running 0 16m
prometheus-k8s-0 2/2 Running 0 16m
prometheus-k8s-1 2/2 Running 0 16m
prometheus-operator-75d9b475d9-jdj87 2/2 Running 0 18m
创建ingress资源
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus-ingress
namespace: monitoring
spec:
rules:
- host: prom.k8s.com
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: prometheus-k8s
port:
number: 9090
- host: grafana.k8s.com
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: grafana
port:
number: 3000
- host: alertmanager.k8s.com
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: alertmanager-main
port:
number: 9093
检查页面
http://prom.k8s.com
http://grafana.k8s.com
http://alertmanager.k8s.com/
2.安装部署
克隆代码
git clone https://github.com/prometheus-operator/kube-prometheus.git
cd kube-prometheus
创建CRD
kubectl apply -f manifests/setup
修改kube-state-metrics的镜像地址
vim manifests/kube-state-metrics-deployment.yaml
- image: bitnami/kube-state-metrics:2.1.1
创建资源
kubectl get servicemonitors --all-namespaces
kubectl apply -f manifests/
查看创建的资源
[root@node1 kube-prometheus]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 16m
alertmanager-main-1 2/2 Running 0 16m
alertmanager-main-2 2/2 Running 0 16m
blackbox-exporter-6798fb5bb4-4q55f 3/3 Running 0 16m
grafana-6ccd8d89f8-sf26x 1/1 Running 0 16m
kube-state-metrics-7fcc9c66b-bqqdm 3/3 Running 0 9s
node-exporter-4f9hz 2/2 Running 0 16m
node-exporter-64hvj 2/2 Running 0 16m
node-exporter-shv72 2/2 Running 0 16m
prometheus-adapter-5df846c94f-5hlhn 1/1 Running 0 16m
prometheus-adapter-5df846c94f-smkxs 1/1 Running 0 16m
prometheus-k8s-0 2/2 Running 0 16m
prometheus-k8s-1 2/2 Running 0 16m
prometheus-operator-75d9b475d9-jdj87 2/2 Running 0 18m
创建ingress资源
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus-ingress
namespace: monitoring
spec:
rules:
- host: prom.k8s.com
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: prometheus-k8s
port:
number: 9090
- host: grafana.k8s.com
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: grafana
port:
number: 3000
- host: alertmanager.k8s.com
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: alertmanager-main
port:
number: 9093
检查页面
http://prom.k8s.com
http://grafana.k8s.com
http://alertmanager.k8s.com/
3.配置监控Scheduler
我们发现kube-scheduler并没有被监控上,查看promtheus的服务发现文件里匹配的是Service的标签
[root@node1 kube-prometheus]# cat manifests/kubernetes-serviceMonitorKubeScheduler.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-scheduler
name: kube-scheduler
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- kube-system
selector: #匹配Service的labels,注意是Service的标签,不是Pod的标签
matchLabels: #下面所有标签都匹配才行
app.kubernetes.io/name: kube-scheduler #具体匹配的标签
但是我们查看kube-system命名空间的service发现并没有kube-scheduler这个Service,所以当然匹配不到。
所以我们需要创建一个Service对象,才能和prometheus的ServiceMonitor关联。
cat > kube-scheduler-svc.yml << 'EOF'
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler #这个标签需要和ServiceMonitor里定义的一样
spec:
selector:
component: kube-scheduler #这个Service关联的是kube-scheduler的Pod的标签
ports:
- name: https-metrics
port: 10259
targetPort: 10259 # 需要注意现在版本默认的安全端口是10259
EOF
这里有两个问题,第一个是component: kube-scheduler这个标签是哪里来的,第二个是端口号码为什么是10259
这两个问题都可以通过查看kube-scheduler的pod的详细信息得到:
[root@node1 kube-prometheus]# kubectl -n kube-system describe pod kube-scheduler-node1
.............
Labels: component=kube-scheduler
tier=control-plane
.............
Liveness: http-get https://127.0.0.1:10259/healthz delay=10s timeout=15s period=10s #success=1 #failure=8
Startup: http-get https://127.0.0.1:10259/healthz delay=10s timeout=15s period=10s #success=1 #failure=24
知道了这两个信息后我们只需要应用一下刚才创建的Service资源即可:
kubectl apply -f kube-scheduler-svc.yml
查看svc
[root@node1 kube-prometheus]# kubectl -n kube-system get svc -l k8s-app=kube-scheduler
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-scheduler ClusterIP 10.1.148.228 <none> 10259/TCP 92s
这时候还是会发现不来了,因为kube-scheduler的配置文件监听的ip地址是监听127.0.0.1,所以访问不了,我们需要修改成0.0.0.0,修改后kube-scheduler会自动重启
cat /etc/kubernetes/manifests/kube-scheduler.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-scheduler
tier: control-plane
name: kube-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=0.0.0.0
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
- --port=0
编写Service
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
selector:
component: kube-scheduler
ports:
- name: https-metrics
port: 10259
targetPort: 10259
修改ServiceMonitor文件
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-scheduler
检查结果:

4.配置监控Controller
查看Controller的详细信息
[root@node1 ~]# kubectl -n kube-system describe pod kube-controller-manager-node1
..............
Labels: component=kube-controller-manager
......
--bind-address=127.0.0.1
......
Liveness: http-get https://127.0.0.1:10257/healthz
..............
修改kube-controller-manager监听地址,修改后会自动重启
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
.......
- --bind-address=0.0.0.0
.......
创建Controller的svc资源配置
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
selector:
component: kube-controller-manager
ports:
- name: https-metrics
port: 10257
targetPort: 10257
修改ServiceMonitor资源
vim manifests/kubernetes-serviceMonitorKubeControllerManager.yaml
..............
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-controller-manager
查看prometheus发现已经自动发现了
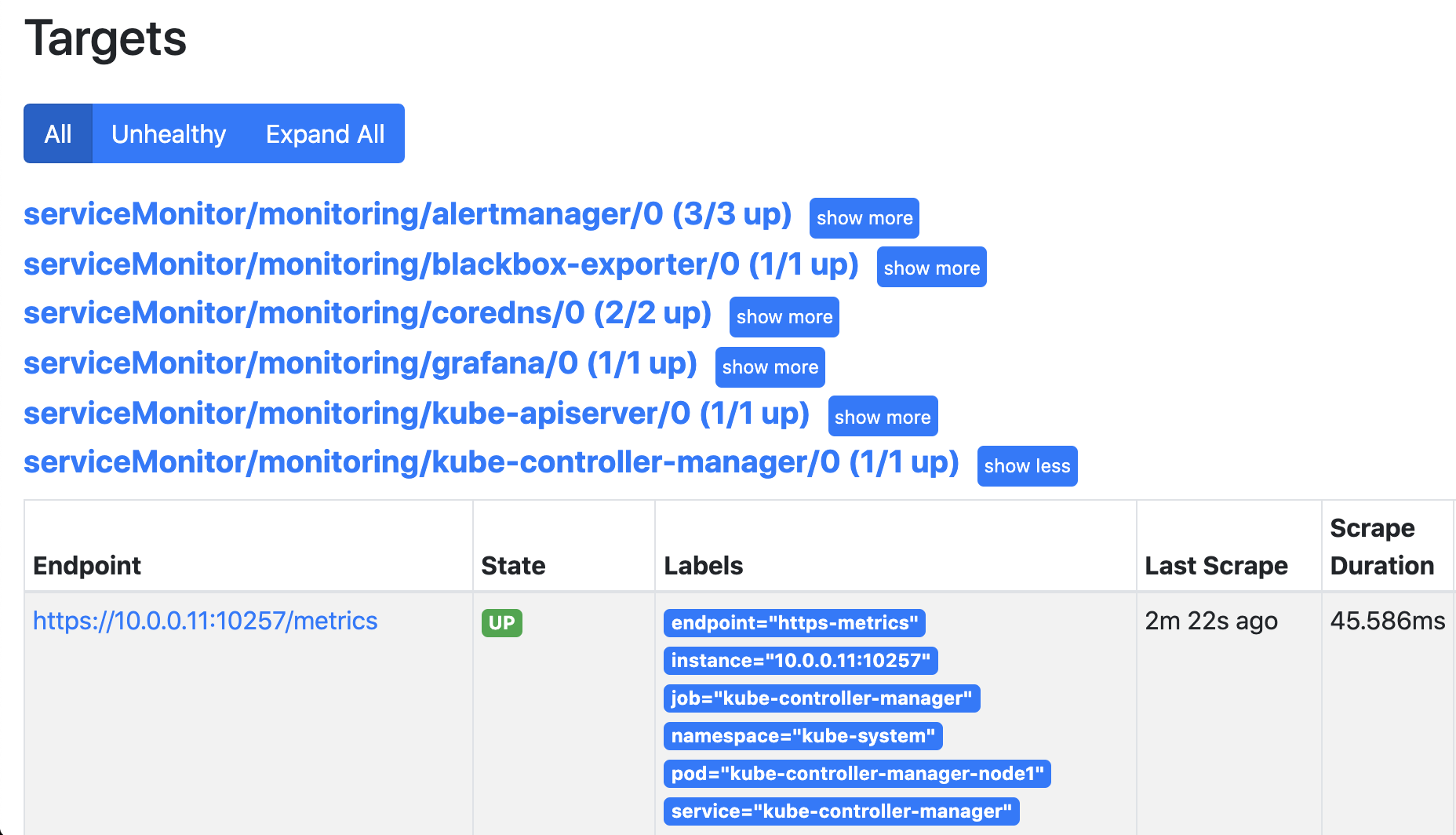
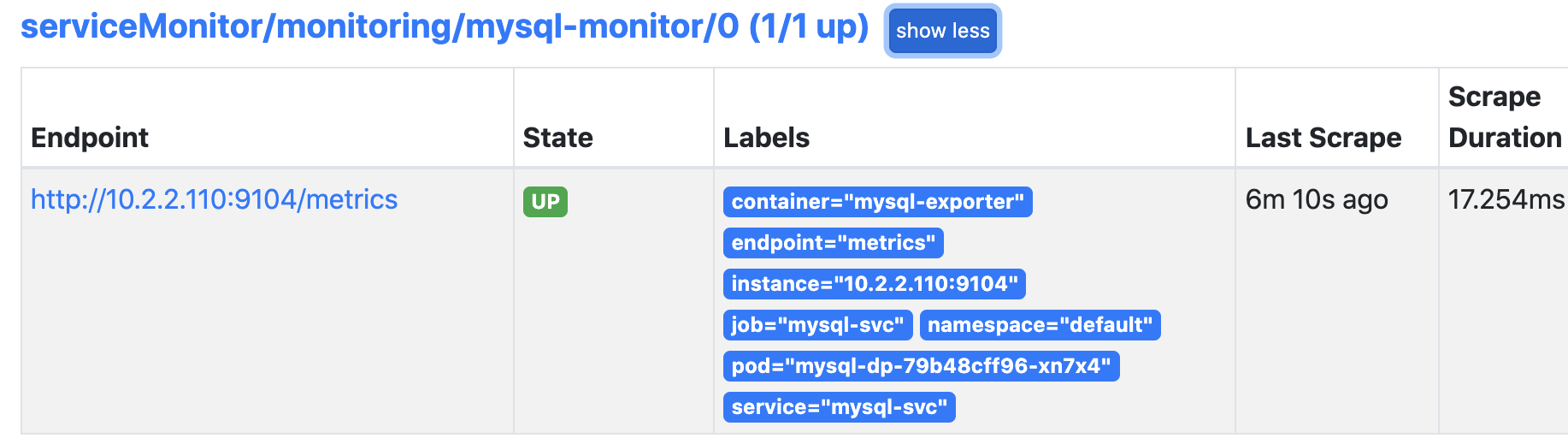
5.配置监控mysql
创建mysql的service
kind: Service
apiVersion: v1
metadata:
name: mysql-svc
labels:
app: mysql
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9104"
spec:
selector:
app: mysql
ports:
- name: mysql
port: 3306
targetPort: 3306
- name: metrics
port: 9104
targetPort: 9104
创建prometheus的ServiceMonitor
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: mysql-monitor
labels:
app: mysql-dp
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token #token文件
interval: 30s #每30s获取一次信息
port: metrics #对应的Service端口名称
jobLabel: k8s-app #用户从中检索任务名称标签
namespaceSelector: #匹配某一个命名空间的Service
matchNames: #匹配的命名空间名称
- default
selector: #匹配的Service的labels
matchLabels:
app: mysql
检查结果:
6.报警配置文件
prometheus-operator模式下,AlertManager配置文件是以secret形式保存的,然后挂载到AlertManager的Pod中,默认配置如下:
apiVersion: v1
kind: Secret
metadata:
labels:
alertmanager: main
app.kubernetes.io/component: alert-router
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.21.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
"global":
"resolve_timeout": "5m"
"inhibit_rules":
- "equal":
- "namespace"
- "alertname"
"source_match":
"severity": "critical"
"target_match_re":
"severity": "warning|info"
- "equal":
- "namespace"
- "alertname"
"source_match":
"severity": "warning"
"target_match_re":
"severity": "info"
"receivers":
- "name": "Default"
- "name": "Watchdog"
- "name": "Critical"
"route":
"group_by":
- "namespace"
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
- "match":
"alertname": "Watchdog"
"receiver": "Watchdog"
- "match":
"severity": "critical"
"receiver": "Critical"
type: Opaque
配置解释:
apiVersion: v1
kind: Secret
metadata:
labels:
alertmanager: main
app.kubernetes.io/component: alert-router
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.21.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
#全局配置
"global":
#告警解析超时时间,表示告警在未收到更新后多长时间被标记为已解决。
"resolve_timeout": "5m"
#告警抑止相关配置
"inhibit_rules":
#匹配规则1
- "equal":
- "namespace"
- "alertname"
#匹配的源标签
"source_match":
#告警级别为critical
"severity": "critical"
#匹配的目标标签,也就是需要抑止的报警级别
"target_match_re":
#告警级别为warning或info
"severity": "warning|info"
#匹配规则2
- "equal":
- "namespace"
- "alertname"
#匹配的源标签
"source_match":
#告警级别为warning
"severity": "warning"
#匹配的目标标签,也就是需要抑止的报警级别
"target_match_re":
#告警级别为info
"severity": "info"
#接收器相关配置
"receivers":
#定义了三个接收器,但是没有具体的配置
- "name": "Default"
- "name": "Watchdog"
- "name": "Critical"
#路由配置,简单来说就是控制什么样的报警信息发给哪个接收器
"route":
#分组依据,根据命名空间分组
"group_by":
- "namespace"
#在发送初始通知之前等待的时间,默认 30 秒。
"group_wait": "30s"
#在同一分组内发送重复通知的间隔,默认 5 分钟。
"group_interval": "5m"
#对同一告警重复发送通知的间隔,默认 12 小时
"repeat_interval": "12h"
#默认的接收器,如果所有转发规则都没匹配上,交给Default接收器处理
"receiver": "Default"
#子路由配置
"routes":
#匹配规则1: 如果报警名称是Watchdog则交给Watchdog接收器处理
- "match":
"alertname": "Watchdog"
"receiver": "Watchdog"
#匹配规则2: 如果报警名称是critical则交给critical接收器处理
- "match":
"severity": "critical"
"receiver": "Critical"
type: Opaque
8.告警抑止
什么是告警抑止和告警风暴?
为了更有效的评估告警事件的严重性,我们一般会对告警信息进行分级,比如灾难,严重,警告,信息等。
但是有一些场景,可能会导致大量的报警信息同一时间一下子爆出来,比如说如果某台服务器宕机了,那么这台服务器上所有的服务都故障了,那么与这些服务相关的报警则统统都会发出来,面对一瞬间发来的海量报警信息,可能会让我们忽略掉真正有意义的关键报警,这就是告警风暴。
还有一种情况,比如我们需要对磁盘剩余使用量进行监控,比如分别在50% 30% 20%的时候发送告警信息,但是这里有一个问题,如果到达了20%的条件,那么50% 30%的告警条件也必然满足,那么我将会收到3份告警信息,但如果已经到达20%的条件了,那么50% 30%就没有必要再告警了,这种场景就是告警抑止。
下面我们通过一个案例来实验告警抑止的效果:
第一步:清除默认自带的配置
kubectl -n monitoring get prometheusrule
kubectl -n monitoring delete prometheusrules $(kubectl -n monitoring get prometheusrules |grep "rules"|awk '{print $1}')
第二步:修改告警配置文件,注释告警抑止相关的配置
apiVersion: v1
kind: Secret
metadata:
labels:
alertmanager: main
app.kubernetes.io/component: alert-router
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.21.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
"global":
"resolve_timeout": "5m"
#"inhibit_rules":
#- "equal":
# - "namespace"
# - "alertname"
# "source_match":
# "severity": "critical"
# "target_match_re":
# "severity": "warning|info"
#- "equal":
# - "namespace"
# - "alertname"
# "source_match":
# "severity": "warning"
# "target_match_re":
# "severity": "info"
"receivers":
- "name": "Default"
- "name": "Watchdog"
- "name": "Critical"
"route":
"group_by":
- "namespace"
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
- "match":
"alertname": "Watchdog"
"receiver": "Watchdog"
- "match":
"severity": "critical"
"receiver": "Critical"
type: Opaque
第三步:创建测试规则文件
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 1.1.2
prometheus: k8s
role: alert-rules
name: node-exporter-rules
namespace: monitoring
spec:
groups:
- name: node-exporter
rules:
- alert: NodeFilesystemSpaceLow
expr: |
node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} * 100 < 90
for: 1m
labels:
alertname: NodeFilesystemSpaceLow
namespace: monitoring
severity: info
annotations:
summary: "Info: Filesystem space is below 90% on {{ $labels.instance }}"
description: "Filesystem on {{ $labels.device }} at {{ $labels.instance }} has less than 90% available space."
- alert: NodeFilesystemSpaceLow
expr: |
node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} * 100 < 80
for: 1m
labels:
alertname: NodeFilesystemSpaceLow
namespace: monitoring
severity: warning
annotations:
summary: "Warning: Filesystem space is below 80% on {{ $labels.instance }}"
description: "Filesystem on {{ $labels.device }} at {{ $labels.instance }} has less than 80% available space."
- alert: NodeFilesystemSpaceLow
expr: |
node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} * 100 < 70
for: 1m
labels:
alertname: NodeFilesystemSpaceLow
namespace: monitoring
severity: critical
annotations:
summary: "Critical: Filesystem space is below 70% on {{ $labels.instance }}"
description: "Filesystem on {{ $labels.device }} at {{ $labels.instance }} has less than 70% available space."
第四步:创造告警条件观察效果
没有告警抑止的情况下,当info级别的条件满足,则三个告警全部触发
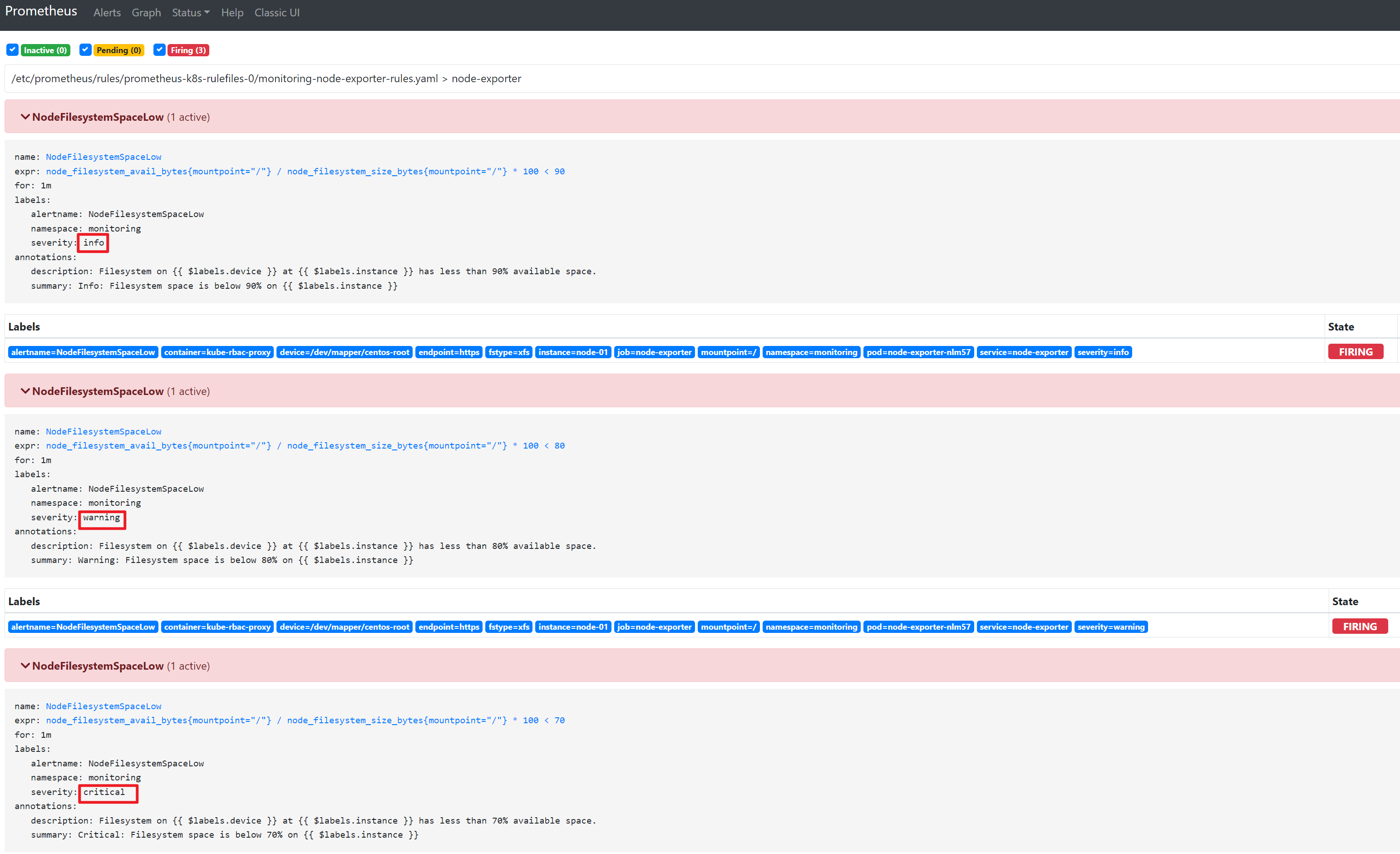
同样,Alertmanager这边也同样收到了三份报警信息
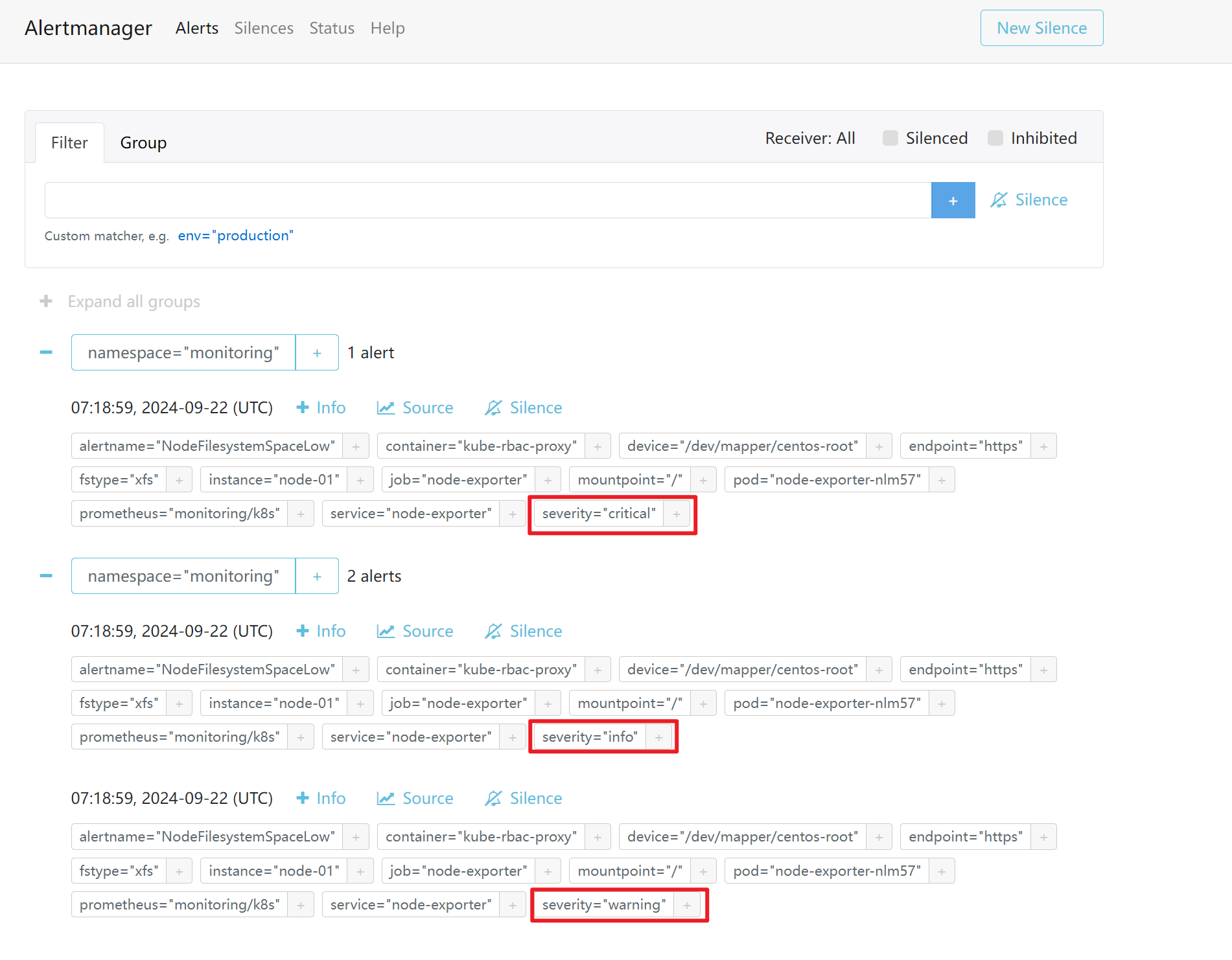
第五步:配置告警抑止的参数
apiVersion: v1
kind: Secret
metadata:
labels:
alertmanager: main
app.kubernetes.io/component: alert-router
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.21.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
"global":
"resolve_timeout": "5m"
"inhibit_rules":
- "equal":
- "namespace"
- "alertname"
"source_match":
"severity": "critical"
"target_match_re":
"severity": "warning|info"
- "equal":
- "namespace"
- "alertname"
"source_match":
"severity": "warning"
"target_match_re":
"severity": "info"
"receivers":
- "name": "Default"
- "name": "Watchdog"
- "name": "Critical"
"route":
"group_by":
- "namespace"
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
- "match":
"alertname": "Watchdog"
"receiver": "Watchdog"
- "match":
"severity": "critical"
"receiver": "Critical"
type: Opaque
第六步:再次测试触发告警后的效果
触发info
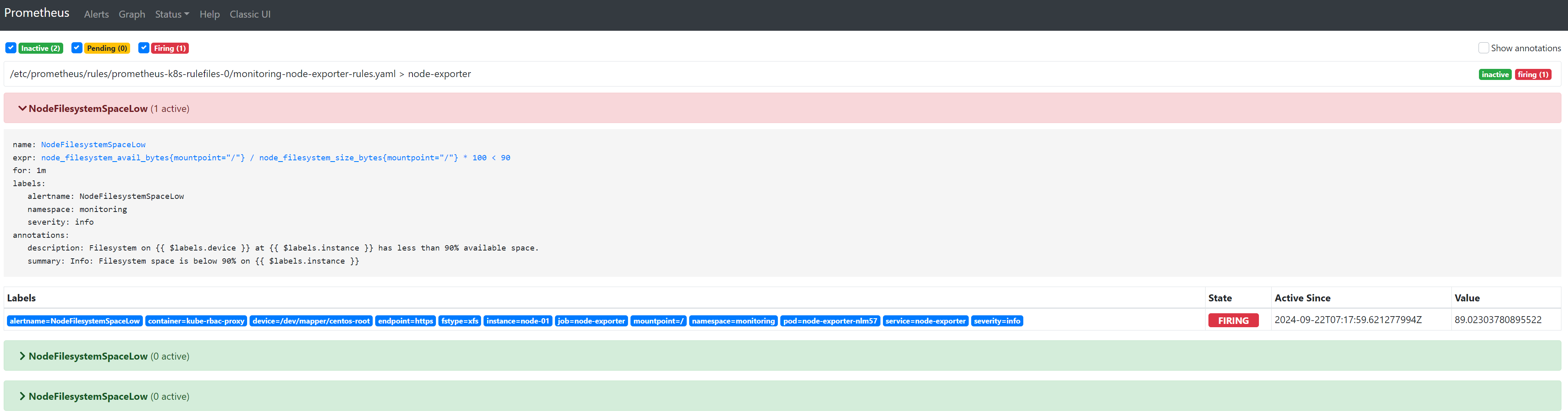
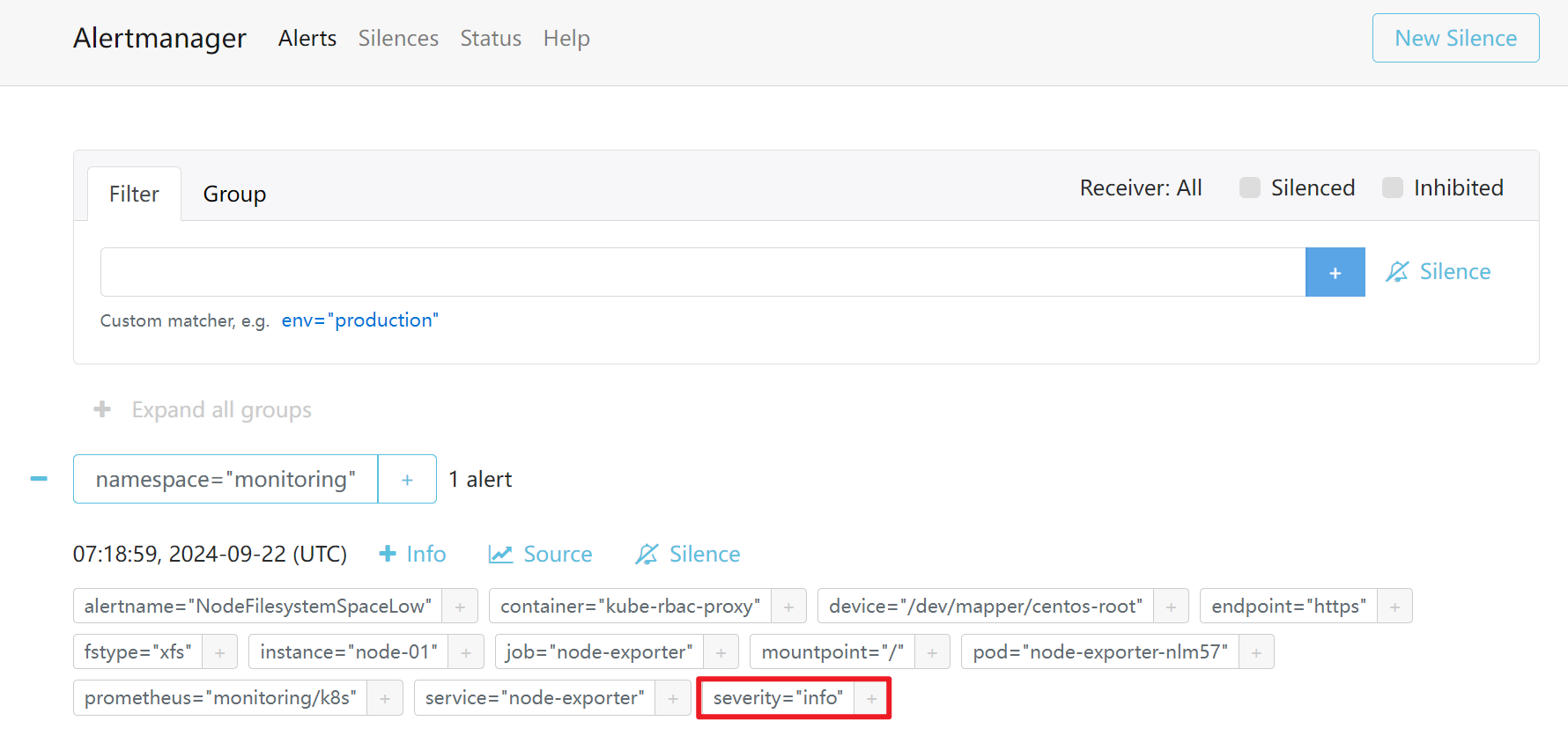
触发warning
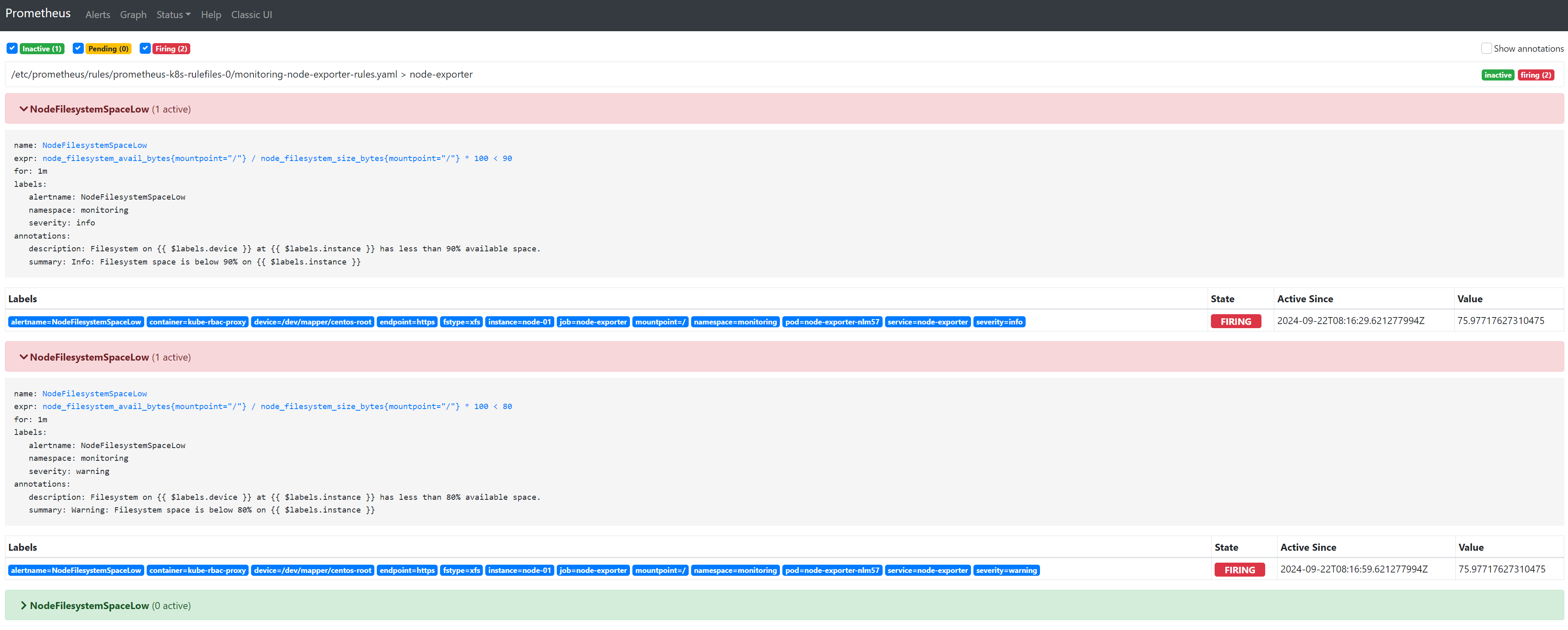
此时会发现只触发了warning的报警信息,info的被抑制了
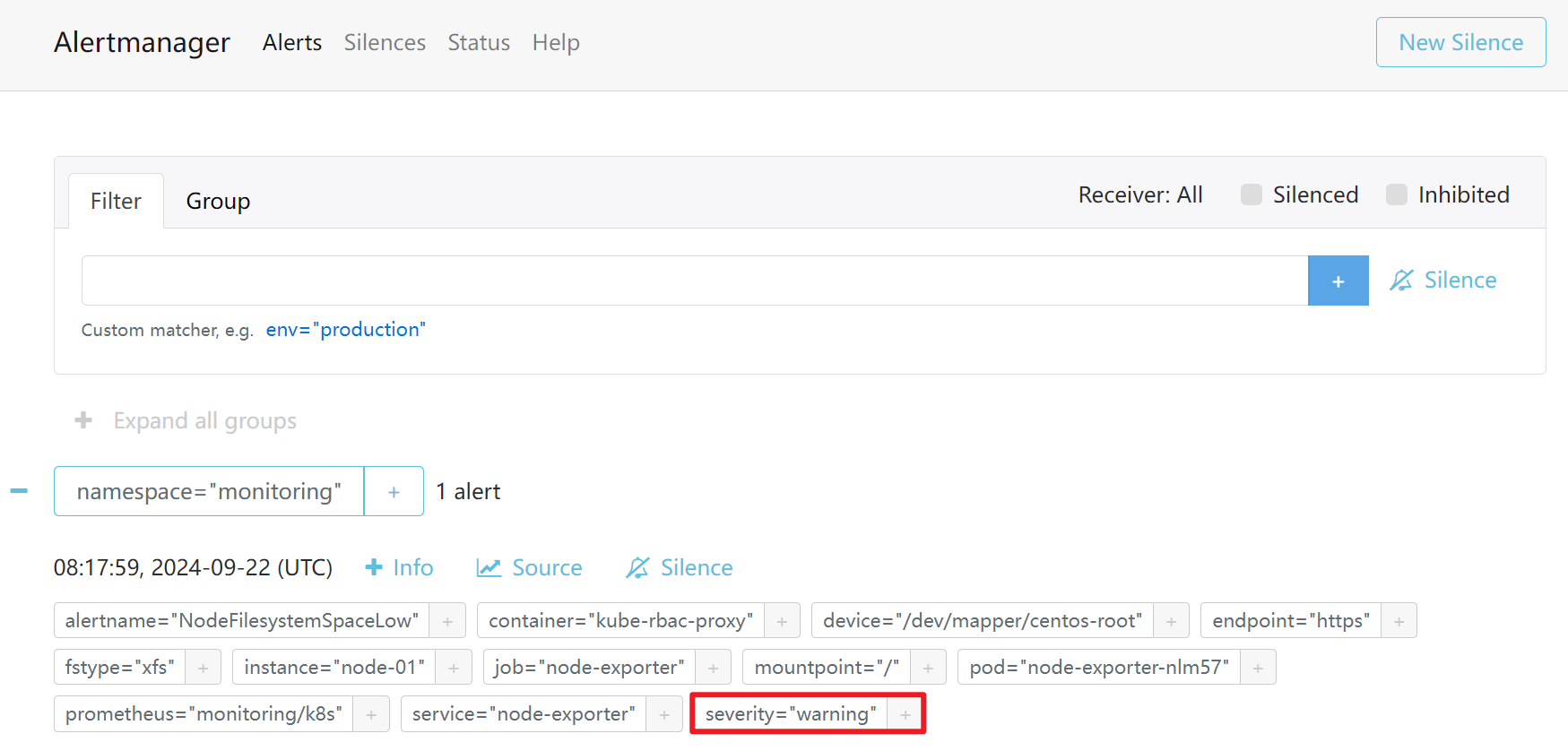
触发critical告警
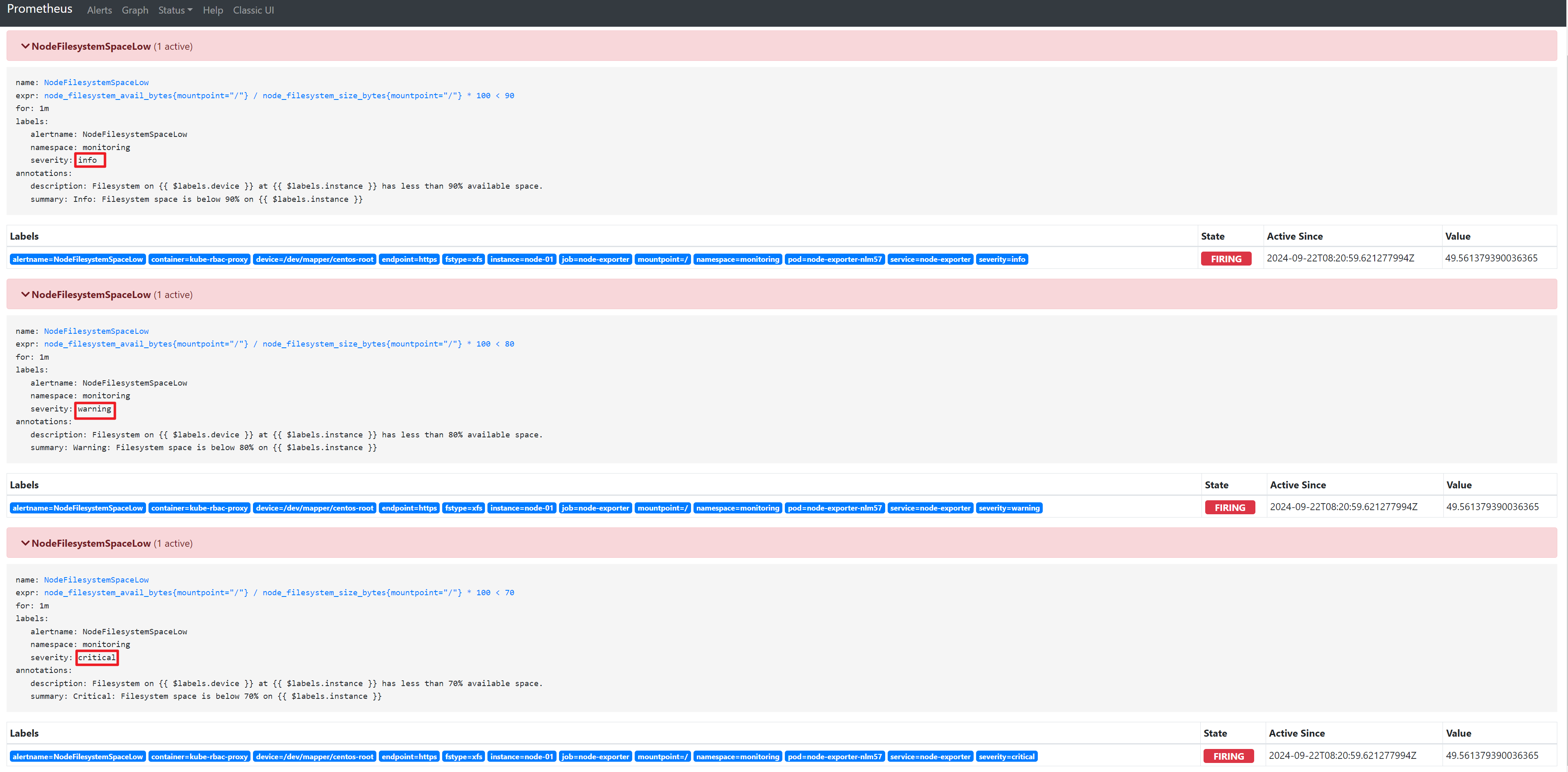
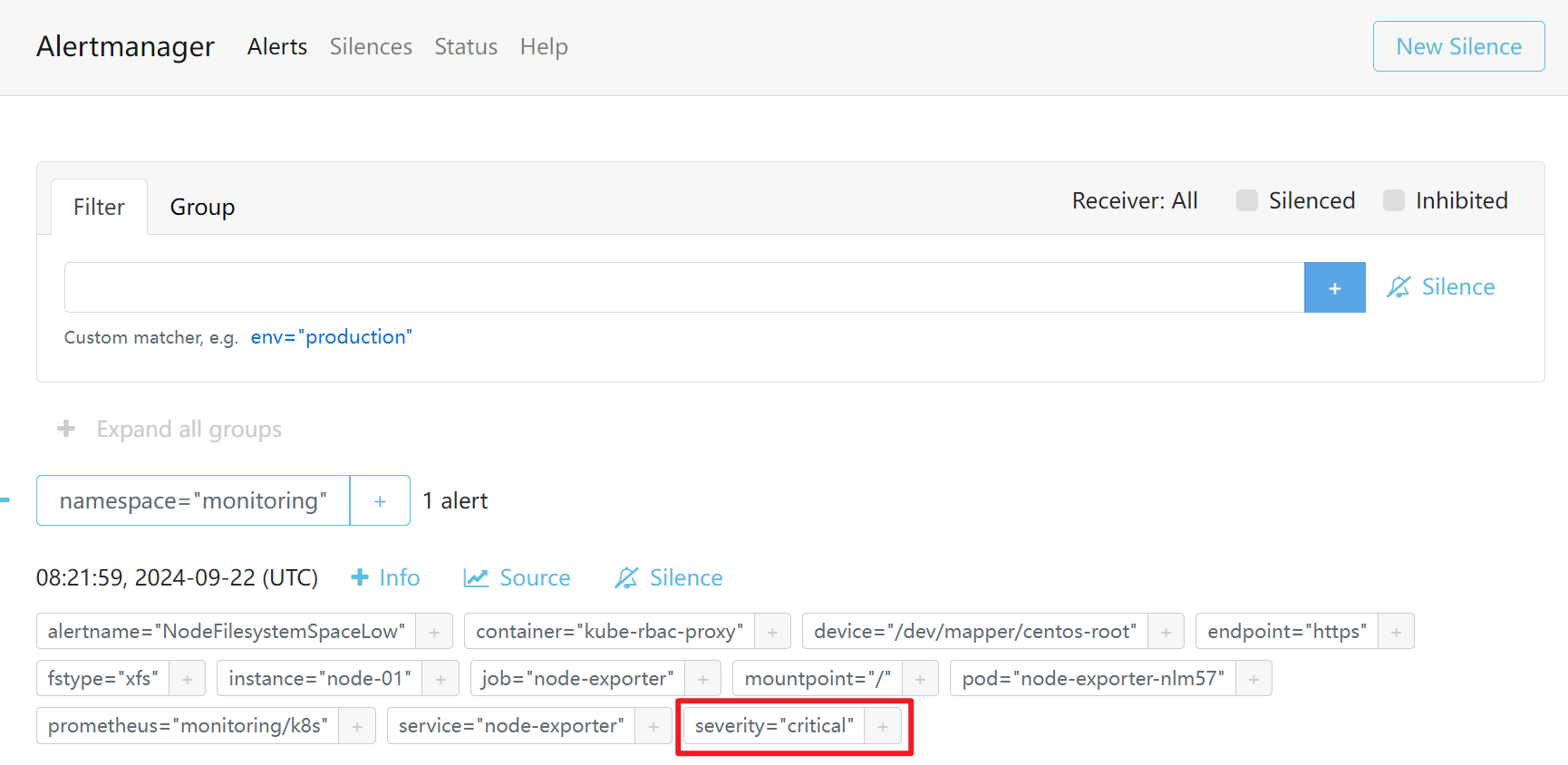
只触发了critical级别的告警,warnning和info的都被抑制了
7.配置邮件报警
默认的报警配置文件虽然定义了接收器,但是接收器没有任何实质的动作,如果我们想将报警发送到邮件里,则需要去定义发送邮件的动作以及配置信息
cat > alertmanager-secret.yaml << 'EOF'
apiVersion: v1
kind: Secret
metadata:
labels:
alertmanager: main
app.kubernetes.io/component: alert-router
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.21.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: 'vim27@qq.com'
smtp_auth_username: 'vim27@qq.com'
smtp_auth_password: 'xxxxxxxxx'
smtp_require_tls: false
inhibit_rules:
- source_match:
severity: 'critical'
target_match_re:
severity: 'warning|info'
equal:
- namespace
- alertname
- source_match:
severity: 'warning'
target_match_re:
severity: 'info'
equal:
- namespace
- alertname
receivers:
- name: 'Default'
email_configs:
- to: 'vim27@qq.com'
send_resolved: true
- name: 'Watchdog'
email_configs:
- to: 'vim27@qq.com'
send_resolved: true
- name: 'Critical'
email_configs:
- to: 'vim27@qq.com'
send_resolved: true
route:
group_by: ['namespace']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: 'Default'
routes:
- match:
alertname: 'Watchdog'
receiver: 'Watchdog'
- match:
severity: 'critical'
receiver: 'Critical'
type: Opaque
EOF
报警规则解释:
cat > alertmanager-secret.yaml << 'EOF'
apiVersion: v1
kind: Secret
metadata:
labels:
alertmanager: main
app.kubernetes.io/component: alert-router
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.21.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
global:
resolve_timeout: 5m
#发送邮件的stmp服务器
smtp_smarthost: 'smtp.qq.com:465'
#发送者的邮箱
smtp_from: 'vim27@qq.com'
#邮箱认证帐号
smtp_auth_username: 'vim27@qq.com'
#邮箱的授权码(不是QQ密码)
smtp_auth_password: 'xxxxxxxxx'
#这里写false,否则发不出去,注意不要加双引或单引
smtp_require_tls: false
inhibit_rules:
- source_match:
severity: 'critical'
target_match_re:
severity: 'warning|info'
equal:
- namespace
- alertname
- source_match:
severity: 'warning'
target_match_re:
severity: 'info'
equal:
- namespace
- alertname
receivers:
#默认接收器
- name: 'Default'
#接收者邮箱
email_configs:
- to: 'vim27@qq.com'
#是否接收恢复信息
send_resolved: true
- name: 'Watchdog'
email_configs:
- to: 'vim27@qq.com'
send_resolved: true
- name: 'Critical'
email_configs:
- to: 'vim27@qq.com'
send_resolved: true
route:
group_by: ['namespace']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: 'Default'
routes:
- match:
alertname: 'Watchdog'
receiver: 'Watchdog'
- match:
severity: 'critical'
receiver: 'Critical'
type: Opaque
EOF
10.webhook对接报警介质
刚才配置的是邮件报警,但是如果我们想将报警发送到钉钉,微信或者飞书,那么这时候就需要另一种配置模式了,也就是webhook模式。
什么是webhook?
webhook的格式就是一串网址信息,然后将参数添加到http的url中,最后由webhook服务端接收,然后进一步处理。
简单来讲,就是AlertManager自己不处理报警信息,而是转发给webhook定义的服务端,相应的服务端收到后,拿到参数进一步的对报警进行相关动作。
比如要想发送钉钉,那就需要有一个dingding的服务端接收信息。
webhook配置参考:
global:
resolve_timeout: 5m
route:
group_by: ['instance']
group_wait: 10m
group_interval: 10s
repeat_interval: 10m
receiver: '[webhook名称]'
receivers:
- name: '[webhook名称]'
webhook_configs:
- url: 'http://[webhook.URL]/prometheusalert?参数&参数&参数'
webhook的配置很简单,但是要实现webhook的服务端,那还需要自己去编写相应的代码,如果不会写也没有关系,因为已经有人帮我们开发了一套很方便的聚合告警平台
11.参考告警规则配置
第一部分:监控指标分类及解释
为了全面监控 Kubernetes 集群的健康状态和性能,我们需要关注以下主要监控指标,并根据它们制定相应的报警规则。
- 集群核心组件监控
- kube-apiserver
- 指标说明:监控 Kubernetes API 服务器的可用性和性能,包括请求速率、错误率、延迟等。
- 关键指标:
apiserver_request_duration_seconds:API 请求的延迟时间。apiserver_request_total:API 请求总数。
- kube-controller-manager
- 指标说明:监控控制器管理器的运行状态,如同步循环的延迟和错误。
- 关键指标:
workqueue_queue_duration_seconds:工作队列中的任务等待时间。workqueue_retries_total:工作队列中任务的重试次数。
- kube-scheduler
- 指标说明:监控调度器的性能和可用性,包括调度延迟和错误。
- 关键指标:
scheduler_scheduling_duration_seconds:调度延迟时间。scheduler_schedule_attempts_total:调度尝试总数。
- kube-apiserver
- 节点资源与系统监控
- node-exporter
- 指标说明:收集节点级别的系统资源使用情况,包括 CPU、内存、磁盘和网络。
- 关键指标:
node_cpu_seconds_total:CPU 使用时间。node_memory_MemAvailable_bytes:可用内存。node_filesystem_free_bytes:磁盘可用空间。node_network_receive_bytes_total/node_network_transmit_bytes_total:网络流量。
- kubelet
- 指标说明:监控 kubelet 的状态,包括容器和 Pod 的运行情况。
- 关键指标:
kubelet_running_pod_count:当前运行的 Pod 数量。kubelet_docker_operations_errors_total:容器操作错误总数。
- node-exporter
- 集群状态与资源监控
- kube-state-metrics
- 指标说明:提供 Kubernetes 资源对象的状态信息,如 Deployment、DaemonSet、StatefulSet、Pod、Service 等。
- 关键指标:
kube_pod_status_phase:Pod 的状态(Pending、Running、Succeeded、Failed)。kube_deployment_status_replicas_unavailable:不可用的 Deployment 副本数。kube_node_status_condition:节点的状态条件(如 Ready、OutOfDisk、MemoryPressure)。
- kube-state-metrics
- 存储与数据库监控
- etcd
- 指标说明:监控 etcd 集群的健康状态和性能。
- 关键指标:
etcd_server_has_leader:etcd 是否有领导者。etcd_server_leader_changes_seen_total:领导者变更次数。etcd_disk_wal_fsync_duration_seconds:磁盘写入延迟。
- etcd
- 监控系统自身监控
- prometheus-k8s
- 指标说明:监控 Prometheus 的性能和运行状态。
- 关键指标:
prometheus_target_scrape_pool_reloads_failed_total:抓取失败次数。prometheus_engine_query_duration_seconds:查询延迟。
- alertmanager
- 指标说明:监控 Alertmanager 的状态,包括告警分发和抑制功能是否正常。
- 关键指标:
alertmanager_alerts:当前告警数量。alertmanager_notifications_failed_total:告警通知失败次数。
- prometheus-k8s
- 网络与服务监控
- blackbox-exporter
- 指标说明:通过主动探测监控服务的可用性和响应时间。
- 关键指标:
probe_success:探测是否成功。probe_duration_seconds:探测耗时。
- ingress-controller
- 指标说明:监控 Ingress 控制器的状态和性能。
- 关键指标:
nginx_ingress_controller_requests:请求总数。nginx_ingress_controller_request_duration_seconds:请求延迟。
- blackbox-exporter
- 应用层监控
- 自定义应用指标
- 指标说明:监控应用程序的特定性能指标,如请求率、错误率、业务指标等。
- 关键指标:
http_requests_total:HTTP 请求总数。http_request_duration_seconds:HTTP 请求延迟。application_error_total:应用错误总数。
- 自定义应用指标
- 安全与合规监控
- Audit Logs
- 指标说明:监控 Kubernetes 集群的安全事件,如未授权访问、配置更改等。
- 关键指标:
kube_audit_event_count:审计事件数量。kube_audit_event_errors:审计事件错误数量。
- Audit Logs
第二部分:Prometheus 报警规则
以下是根据上述监控指标制定的详细 Prometheus 报警规则,按照分类进行整理,并添加了必要的注释。报警级别分为:info、warning、critical。
groups:
- name: 集群核心组件告警规则
rules:
- alert: Kubernetes API 服务器请求延迟过高
expr: histogram_quantile(0.99, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le)) > 1
for: 5m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: API 服务器请求延迟过高"
description: "{{$labels.instance}} 的 99% API 请求延迟超过 1 秒(当前:{{ $value | printf \"%.2f\" }} 秒)。"
- alert: Kubernetes API 服务器错误率过高
expr: sum(rate(apiserver_request_total{code=~"5.."}[5m])) / sum(rate(apiserver_request_total[5m])) > 0.05
for: 5m
labels:
severity: critical
annotations:
summary: "{{$labels.instance}}: API 服务器错误率过高"
description: "{{$labels.instance}} 的 API 请求错误率超过 5%(当前:{{ ($value * 100) | printf \"%.2f\" }}%)。"
- alert: 控制器管理器同步延迟过高
expr: histogram_quantile(0.99, sum(rate(workqueue_queue_duration_seconds_bucket{job="kube-controller-manager"}[5m])) by (le)) > 1
for: 5m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 控制器同步延迟过高"
description: "{{$labels.instance}} 的控制器同步延迟超过 1 秒(当前:{{ $value | printf \"%.2f\" }} 秒)。"
- alert: 调度器调度失败率过高
expr: sum(rate(scheduler_schedule_attempts_total{result="error"}[5m])) / sum(rate(scheduler_schedule_attempts_total[5m])) > 0.1
for: 5m
labels:
severity: critical
annotations:
summary: "{{$labels.instance}}: 调度器调度失败率过高"
description: "{{$labels.instance}} 的调度失败率超过 10%(当前:{{ ($value * 100) | printf \"%.2f\" }}%)。"
- name: 节点资源与系统告警规则
rules:
- alert: 节点宕机
expr: up{job="node-exporter"} == 0
for: 5m
labels:
severity: critical
annotations:
summary: "{{$labels.instance}}: 节点宕机"
description: "节点 {{$labels.instance}} 无法访问,请立即检查。"
- alert: 节点 CPU 使用率过高
expr: (1 - avg by(instance)(irate(node_cpu_seconds_total{mode="idle"}[5m]))) * 100 > 90
for: 3m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: CPU 使用率过高"
description: "节点 {{$labels.instance}} 的 CPU 使用率超过 90%(当前:{{ $value | printf \"%.2f\" }}%)。"
- alert: 节点内存使用率过高
expr: (1 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 90
for: 3m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 内存使用率过高"
description: "节点 {{$labels.instance}} 的内存使用率超过 90%(当前:{{ $value | printf \"%.2f\" }}%)。"
- alert: 节点磁盘空间不足
expr: (node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_avail_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} * 100 > 80
for: 3m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 根分区磁盘使用率过高"
description: "节点 {{$labels.instance}} 的根分区磁盘使用率超过 80%(当前:{{ $value | printf \"%.2f\" }}%)。"
- alert: 节点磁盘 IO 等待时间过长
expr: avg by(instance)(irate(node_disk_io_time_seconds_total[5m])) > 0.5
for: 5m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 磁盘 IO 等待时间过长"
description: "节点 {{$labels.instance}} 的磁盘 IO 等待时间超过 50%(当前:{{ ($value * 100) | printf \"%.2f\" }}%)。"
- alert: 节点网络错误率过高
expr: (sum by(instance)(rate(node_network_receive_errs_total[5m])) + sum by(instance)(rate(node_network_transmit_errs_total[5m]))) > 0
for: 5m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 网络错误率过高"
description: "节点 {{$labels.instance}} 存在网络错误,请检查网络接口。"
- name: 集群状态与资源告警规则
rules:
- alert: 节点未就绪
expr: kube_node_status_condition{condition="Ready",status!="true"} == 1
for: 5m
labels:
severity: critical
annotations:
summary: "节点 {{$labels.node}} 未就绪"
description: "节点 {{$labels.node}} 状态为 NotReady,请检查节点状态。"
- alert: Pod CrashLoopBackOff
expr: kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff"} > 0
for: 5m
labels:
severity: warning
annotations:
summary: "Pod {{$labels.pod}} 处于 CrashLoopBackOff 状态"
description: "Pod {{$labels.namespace}}/{{$labels.pod}} 的容器 {{$labels.container}} 发生 CrashLoopBackOff。"
- alert: Deployment 副本不足
expr: kube_deployment_status_replicas_available / kube_deployment_spec_replicas < 0.9
for: 5m
labels:
severity: warning
annotations:
summary: "Deployment {{$labels.deployment}} 副本不足"
description: "Deployment {{$labels.namespace}}/{{$labels.deployment}} 的可用副本少于 90%。"
- alert: DaemonSet 未完全运行
expr: kube_daemonset_status_number_unavailable > 0
for: 5m
labels:
severity: warning
annotations:
summary: "DaemonSet {{$labels.daemonset}} 未完全运行"
description: "DaemonSet {{$labels.namespace}}/{{$labels.daemonset}} 有未运行的副本。"
- name: 存储与数据库告警规则
rules:
- alert: etcd 集群无领导者
expr: etcd_server_has_leader == 0
for: 1m
labels:
severity: critical
annotations:
summary: "etcd 集群无领导者"
description: "etcd 集群中没有领导者,集群可能不可用。"
- alert: etcd 领导者变更频繁
expr: increase(etcd_server_leader_changes_seen_total[1h]) > 3
for: 5m
labels:
severity: warning
annotations:
summary: "etcd 领导者频繁变更"
description: "etcd 在过去一小时内领导者变更超过 3 次。"
- alert: etcd 磁盘写入延迟过高
expr: histogram_quantile(0.99, sum(rate(etcd_disk_wal_fsync_duration_seconds_bucket[5m])) by (le)) > 0.1
for: 5m
labels:
severity: warning
annotations:
summary: "etcd 磁盘写入延迟过高"
description: "etcd 磁盘写入延迟超过 100ms(当前:{{ ($value * 1000) | printf \"%.2f\" }} ms)。"
- name: 监控系统自身告警规则
rules:
- alert: Prometheus 抓取失败
expr: up{job="prometheus-k8s"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Prometheus 实例 {{$labels.instance}} 抓取失败"
description: "Prometheus 实例 {{$labels.instance}} 无法抓取指标,请检查服务状态。"
- alert: Prometheus 查询延迟过高
expr: histogram_quantile(0.99, sum(rate(prometheus_engine_query_duration_seconds_bucket[5m])) by (le)) > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Prometheus 查询延迟过高"
description: "Prometheus 查询延迟超过 2 秒(当前:{{ $value | printf \"%.2f\" }} 秒)。"
- alert: Alertmanager 通知失败
expr: increase(alertmanager_notifications_failed_total[5m]) > 0
for: 5m
labels:
severity: warning
annotations:
summary: "Alertmanager 通知失败"
description: "Alertmanager 发送通知失败,请检查通知渠道配置。"
- name: 网络与服务告警规则
rules:
- alert: 服务探测失败
expr: probe_success == 0
for: 1m
labels:
severity: critical
annotations:
summary: "服务 {{$labels.instance}} 探测失败"
description: "Blackbox Exporter 探测到服务 {{$labels.instance}} 不可用,请检查服务状态。"
- alert: Ingress 控制器请求错误率过高
expr: sum(rate(nginx_ingress_controller_requests{status=~"5.."}[5m])) / sum(rate(nginx_ingress_controller_requests[5m])) > 0.05
for: 5m
labels:
severity: warning
annotations:
summary: "Ingress 控制器请求错误率过高"
description: "Ingress 控制器请求错误率超过 5%(当前:{{ ($value * 100) | printf \"%.2f\" }}%)。"
- alert: Ingress 控制器请求延迟过高
expr: histogram_quantile(0.99, sum(rate(nginx_ingress_controller_request_duration_seconds_bucket[5m])) by (le)) > 1
for: 5m
labels:
severity: warning
annotations:
summary: "Ingress 控制器请求延迟过高"
description: "Ingress 控制器 99% 请求延迟超过 1 秒(当前:{{ $value | printf \"%.2f\" }} 秒)。"
- name: 应用层告警规则
rules:
- alert: 应用请求错误率过高
expr: sum(rate(http_requests_total{status=~"5.."}[5m])) / sum(rate(http_requests_total[5m])) > 0.05
for: 5m
labels:
severity: critical
annotations:
summary: "应用 {{$labels.app}} 请求错误率过高"
description: "应用 {{$labels.app}} 的请求错误率超过 5%(当前:{{ ($value * 100) | printf \"%.2f\" }}%)。"
- alert: 应用请求延迟过高
expr: histogram_quantile(0.99, sum(rate(http_request_duration_seconds_bucket[5m])) by (le)) > 2
for: 5m
labels:
severity: warning
annotations:
summary: "应用 {{$labels.app}} 请求延迟过高"
description: "应用 {{$labels.app}} 的 99% 请求延迟超过 2 秒(当前:{{ $value | printf \"%.2f\" }} 秒)。"
- alert: 应用错误数量激增
expr: increase(application_error_total[5m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "应用 {{$labels.app}} 错误数量激增"
description: "应用 {{$labels.app}} 在 5 分钟内发生了超过 100 次错误。"
- name: 安全与合规告警规则
rules:
- alert: 未授权的 Kubernetes API 请求
expr: sum(rate(apiserver_request_total{code="403"}[5m])) > 10
for: 5m
labels:
severity: warning
annotations:
summary: "未授权的 API 请求数量过多"
description: "在过去 5 分钟内,未授权的 API 请求数量超过 10 次。"
- alert: 节点高负载
expr: node_load1 / count(node_cpu_seconds_total{mode="system"}) * 100 > 80
for: 5m
labels:
severity: warning
annotations:
summary: "节点 {{$labels.instance}} 系统负载过高"
description: "节点 {{$labels.instance}} 的 1 分钟平均负载超过 80%(当前:{{ $value | printf \"%.2f\" }}%)。"
- alert: 内核错误日志
expr: rate(node_kernel_errors[5m]) > 0
for: 5m
labels:
severity: warning
annotations:
summary: "节点 {{$labels.instance}} 内核错误"
description: "节点 {{$labels.instance}} 发现内核错误日志,请检查系统日志。"
- name: 自定义指标告警规则
rules:
- alert: HPA 无法获取指标
expr: kube_horizontalpodautoscaler_status_current_metrics == 0
for: 5m
labels:
severity: warning
annotations:
summary: "HPA {{$labels.hpa}} 无法获取指标"
description: "HPA {{$labels.namespace}}/{{$labels.hpa}} 无法获取所需的指标,自动伸缩可能受影响。"
- alert: 自定义应用指标异常
expr: my_custom_metric{job="my_app"} > threshold_value
for: 5m
labels:
severity: warning
annotations:
summary: "应用 {{$labels.app}} 自定义指标异常"
description: "应用 {{$labels.app}} 的自定义指标超过阈值(当前:{{ $value }})。"
- alert: 应用实例数量不足
expr: count(up{job="my_app"}) < desired_instance_count
for: 5m
labels:
severity: critical
annotations:
summary: "应用 {{$labels.app}} 实例数量不足"
description: "应用 {{$labels.app}} 的实例数量少于预期(当前:{{ $value }})。"
注释说明:
- groups:定义告警规则的分组,方便管理和维护。
- name:告警规则组的名称,表明该组的告警范围或主题。
- rules:具体的告警规则列表。
- alert:告警名称,简洁描述问题。
- expr:PromQL 表达式,定义告警触发条件。
- for:持续时间,表达式需在该时间段内持续为真才会触发告警,避免短暂波动引发误报。
- labels:告警的标签信息。
- severity:告警级别,分为
info、warning、critical,用于告警分级和路由。
- severity:告警级别,分为
- annotations:告警的详细信息。
- summary:告警摘要,提供简要描述,通常用于通知标题。
- description:告警详细描述,包含具体信息和变量,帮助快速定位问题。
变量说明:
- {{$labels.instance}}:触发告警的实例 IP 或主机名。
- {{$labels.node}}:节点名称。
- {{$labels.pod}}:Pod 名称。
- {{$labels.namespace}}:命名空间名称。
- {{$labels.deployment}}:Deployment 名称。
- {{$labels.daemonset}}:DaemonSet 名称。
- {{$labels.container}}:容器名称。
- {{$labels.app}}:应用名称。
- {{$labels.hpa}}:Horizontal Pod Autoscaler 名称。
- {{ $value }}:表达式计算出的当前值,可用于在描述中提供实时数据。
注意事项:
- 告警级别设置:根据告警的严重程度合理设置
severity,以便在通知时进行优先级区分。 - 表达式调整:根据实际的集群环境和指标数据,对 PromQL 表达式进行调整,确保告警的准确性和有效性。
- **持续时间 **
for:根据指标的波动特性,合理设置for的持续时间,平衡告警的及时性和准确性,避免频繁的告警抖动。 - 阈值设置:对于需要设定阈值的告警(如 CPU 使用率、错误率等),应根据历史数据和业务需求设定合理的阈值。
- 自定义指标:在应用层告警规则和自定义指标告警规则中,需要根据具体的应用程序和业务逻辑,定制相应的指标和阈值。
分类整理的好处:
- 提高可读性:按照功能或组件分类整理告警规则,方便查看和管理。
- 便于维护:当需要修改或新增告警规则时,可以快速定位到相应的规则组。
- 增强可扩展性:未来添加新的监控组件或指标时,可以按照现有的分类方式,轻松扩展告警规则。
更新: 2024-09-22 17:39:42