第2章 Kafka重要概念
1.什么是kafka
Kafka 是一个分布式流处理平台,最初由LinkedIn开发,后来开源并贡献给了Apache基金会。它主要用于构建实时数据管道和流应用程序。Kafka的核心理念是将消息流从一个地方传送到另一个地方,具备高吞吐量、低延迟、水平扩展能力,能够处理大量的实时数据。
Kafka的使用场景非常广泛,主要应用于日志聚合、实时监控、事件驱动系统、流式数据处理、消息队列系统等。它能处理从各种源头(例如日志、传感器数据、交易数据)采集的大量数据,并将这些数据实时传送到目标系统中。
2.kafka核心概念
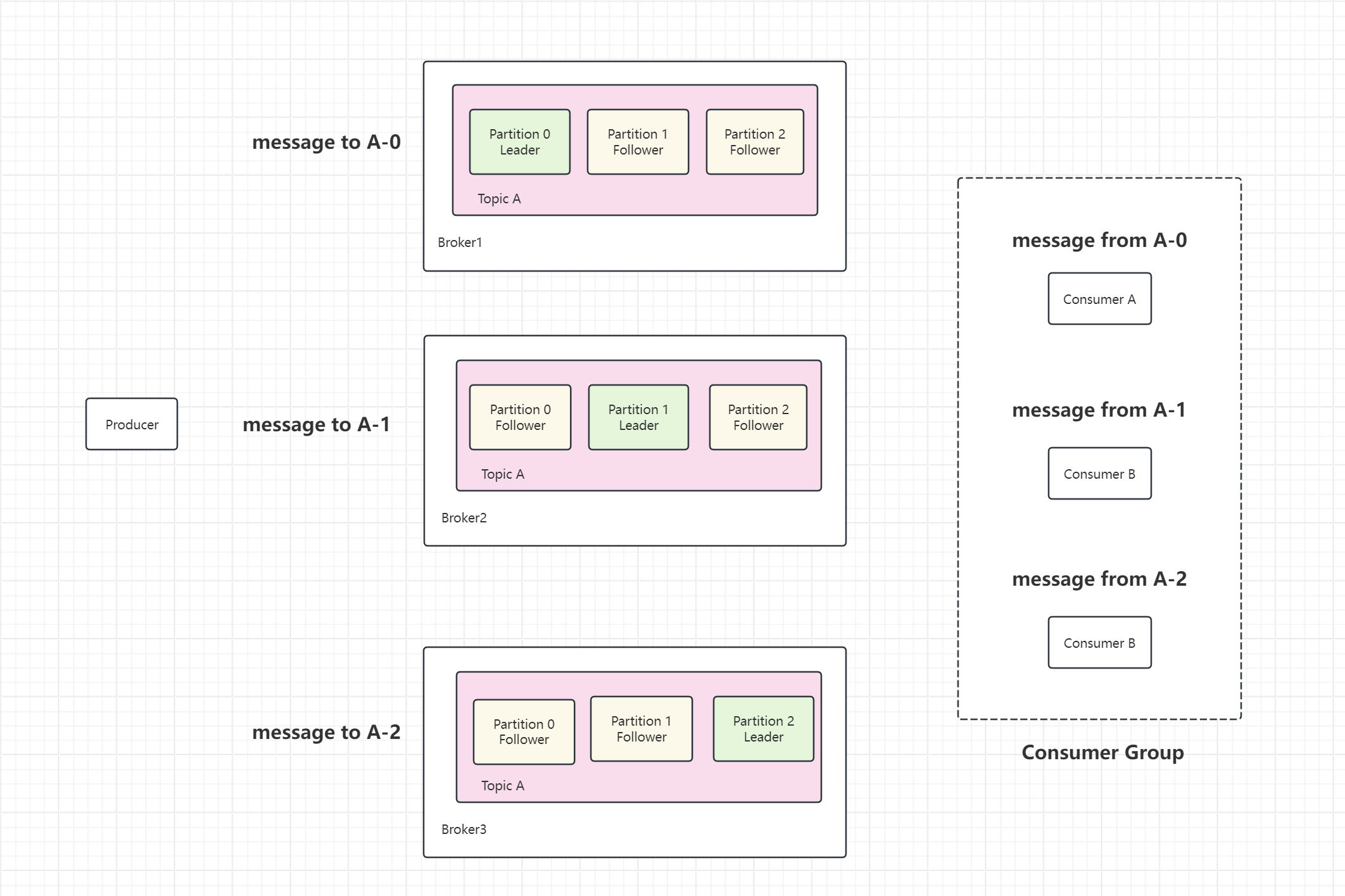
Producer(生产者):生成消息并将其发送到Kafka主题的客户端应用程序。
Consumer(消费者):从Kafka主题读取消息的客户端应用程序。
Broker:Kafka集群中的服务器,负责存储和传输数据。一个Kafka集群包含多个Broker,所有消息都被存储在它们的磁盘上。
Topic(主题):Kafka中用来分类消息的逻辑单元。每个主题包含若干个分区。
Partition(分区):主题的子集,Kafka将一个主题拆分为多个分区以实现并行处理和负载均衡。
Replica(副本):分区的副本,保证了分区的高可用性。Kafka为每个分区保存多个副本,其中一个副本被选为Leader,其余副本作为Follower。
Offset:每条消息在分区中的唯一标识符。消费者使用Offset追踪它已处理的消息。
Consumer Group(消费者组):多个消费者可以组成一个消费者组,消费者组内的每个消费者都会从不同的分区消费消息,从而实现负载均衡。
Lag: 消息堆积
3.kafka与zookeeper的关系
Kafka使用Zookeeper作为分布式协调工具,主要用于管理Kafka集群的元数据和配置,以下是具体的几点关系:
集群管理:Zookeeper负责追踪Kafka集群中所有Broker的状态,确保Kafka的Broker能够动态加入或退出集群。
Leader选举:Zookeeper帮助Kafka进行分区副本的Leader选举。在每个分区中,只有一个副本是Leader,负责处理所有的读写请求,其余副本作为Follower进行同步。Zookeeper确保当Leader失效时,能够快速选举出新的Leader。
元数据管理:Zookeeper维护着Kafka集群的所有元数据,包括主题、分区、副本的配置信息等。消费者和生产者可以通过Zookeeper了解集群的状态和拓扑结构。
Kafka最新版本已经逐步去除对Zookeeper的依赖,转向使用自身的Kafka Raft协议(KRaft)进行集群管理和Leader选举。这是为了简化架构并减少对外部系统的依赖。
4.kafka处理消息流程
1)消息生产
生产者发送消息到指定的 Kafka 主题。
消息基于键或轮询策略分配到特定分区。
2)数据存储
领导者副本首先接收并写入消息到磁盘。
消息从领导者复制到所有追随者副本。
消息在多个副本间同步后被视为已提交。
3)消息消费
消费者从订阅的主题拉取消息。
消费者根据读取的偏移量消费消息,并可提交新的偏移量以跟踪进度。
4)故障处理
如果领导者副本失败,将从同步副本中选择新的领导者。
如果消费者失败,其分区将被重新分配给同一群组的其他消费者。
5.kafka的版本选择
更新: 2025-04-07 14:48:51