第3章 Kafka集群架构
1.kafka集群架构
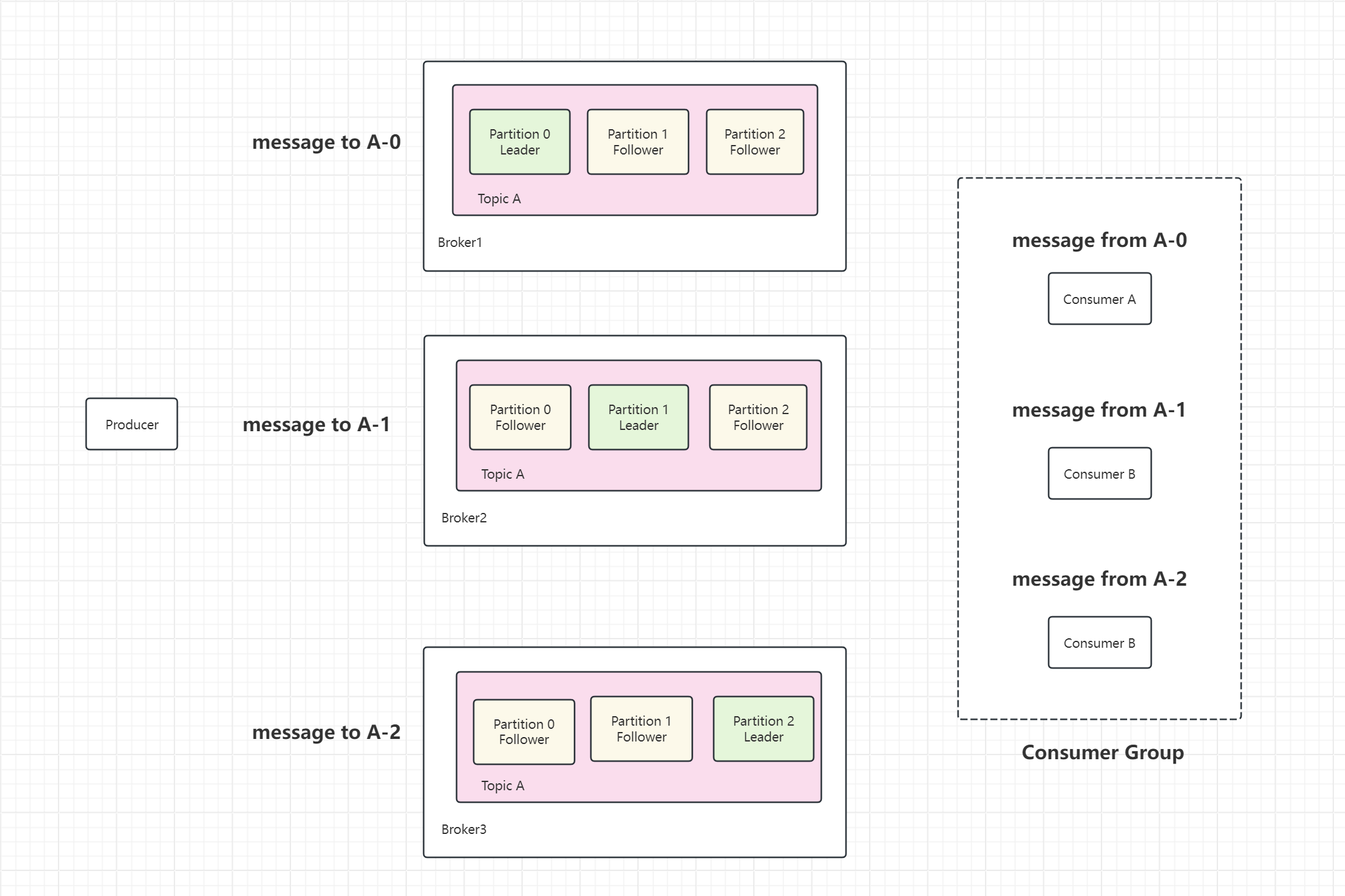
2.kafka集群部署(三台机器都操作)
软件包
安装jdk
tar zxf jdk-11.0.13+8.tar.gz -C /opt/
ln -s /opt/jdk-11.0.13+8 /opt/jdk
cp /etc/profile /etc/profile.bak
cat >> /etc/profile << 'EOF'
export JAVA_HOME=/opt/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin
EOF
source /etc/profile
java -version
echo $JAVA_HOME
echo $JRE_HOME
安装zookeeper集群 (注意!三台机器的配置一样,但是id不一样)
配置解释:
# tickTime: ZooKeeper中使用的基本时间单位,以毫秒为单位。这个时间用来控制心跳和超时。默认是2000毫秒(2秒)。
tickTime=2000
# initLimit: 这个配置项用来配置在启动过程中,follower可以与leader进行同步的初始化时间,以tickTime的倍数计算。这里设置为10,意味着允许10个tickTime的时间来完成初始化。
initLimit=10
# syncLimit: 这个配置项用来设置follower与leader同步时的最长等待时间,也是以tickTime的倍数计算。这里设置为5,意味着在5个tickTime时间内,follower需要与leader完成同步。
syncLimit=5
# dataDir: ZooKeeper保存数据的目录。这个配置项必须设置,因为所有的重要数据都存储在这里。
dataDir=/data/zookeeper
# clientPort: 客户端连接ZooKeeper服务器的端口。默认端口是2181。
clientPort=2181
# server.X=<IP地址>:<通讯端口>:<选举端口>
# 这些是集群中各个服务器的配置。每个server.X的X代表一个服务器的唯一标识符。
# 通讯端口用于服务器间的通讯(默认为2888),选举端口用于选举leader(默认为3888)。
server.1=10.0.0.51:2888:3888
server.2=10.0.0.52:2888:3888
server.3=10.0.0.53:2888:3888
db-51:
tar zxf apache-zookeeper-3.7.0-bin.tar.gz -C /opt/
ln -s /opt/apache-zookeeper-3.7.0-bin/ /opt/zookeeper
mkdir -p /data/zookeeper
cp /opt/zookeeper/conf/zoo_sample.cfg /opt/zookeeper/conf/zoo.cfg
cat >/opt/zookeeper/conf/zoo.cfg<<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
server.1=10.0.0.51:2888:3888
server.2=10.0.0.52:2888:3888
server.3=10.0.0.53:2888:3888
EOF
echo "1" > /data/zookeeper/myid
cat /data/zookeeper/myid
db-52:
tar zxf apache-zookeeper-3.7.0-bin.tar.gz -C /opt/
ln -s /opt/apache-zookeeper-3.7.0-bin/ /opt/zookeeper
mkdir -p /data/zookeeper
cp /opt/zookeeper/conf/zoo_sample.cfg /opt/zookeeper/conf/zoo.cfg
cat >/opt/zookeeper/conf/zoo.cfg<<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
server.1=10.0.0.51:2888:3888
server.2=10.0.0.52:2888:3888
server.3=10.0.0.53:2888:3888
EOF
echo "2" > /data/zookeeper/myid
cat /data/zookeeper/myid
db-53:
tar zxf apache-zookeeper-3.7.0-bin.tar.gz -C /opt/
ln -s /opt/apache-zookeeper-3.7.0-bin/ /opt/zookeeper
mkdir -p /data/zookeeper
cp /opt/zookeeper/conf/zoo_sample.cfg /opt/zookeeper/conf/zoo.cfg
cat >/opt/zookeeper/conf/zoo.cfg<<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
server.1=10.0.0.51:2888:3888
server.2=10.0.0.52:2888:3888
server.3=10.0.0.53:2888:3888
EOF
echo "3" > /data/zookeeper/myid
cat /data/zookeeper/myid
安装kafka集群(三台机器不一样)
db-51:
tar zxf kafka_2.13-3.2.0.tgz -C /opt/
ln -s /opt/kafka_2.13-3.2.0/ /opt/kafka
mkdir -p /data/kafka/logs
cat > /opt/kafka/config/server.properties << EOF
# 设置每个broker的唯一ID,必须在集群中是唯一的
broker.id=1
# 配置监听地址,确保与服务器IP一致
listeners=PLAINTEXT://10.0.0.51:9092
# 配置网络线程数,根据服务器核心数调整
num.network.threads=3
# 配置I/O线程数,通常设置为处理器的核心数
num.io.threads=8
# Socket发送缓冲区的大小
socket.send.buffer.bytes=102400
# Socket接收缓冲区的大小
socket.receive.buffer.bytes=102400
# 请求的最大字节数,用于防止内存溢出
socket.request.max.bytes=104857600
# 日志文件存储的目录
log.dirs=/data/kafka/logs
# 分区数,每个主题的默认分区数
num.partitions=3
# 每个数据目录的数据恢复线程数
num.recovery.threads.per.data.dir=1
# 偏移量主题的副本因子,应至少等于集群中的节点数减一,以确保高可用
offsets.topic.replication.factor=3
# 事务状态日志的副本因子,应设置为集群节点数以确保事务的持久性
transaction.state.log.replication.factor=3
# 最小同步副本数,设置为2以确保至少有一个副本同步
transaction.state.log.min.isr=2
# 日志保留时间,24小时
log.retention.hours=24
# 单个日志文件的最大大小
log.segment.bytes=1073741824
# 日志保留检查间隔,单位毫秒
log.retention.check.interval.ms=300000
# Zookeeper集群的连接字符串
zookeeper.connect=10.0.0.51:2181,10.0.0.52:2181,10.0.0.53:2181
# Zookeeper连接超时时间,单位毫秒
zookeeper.connection.timeout.ms=6000
# 初始重平衡延迟,设置为0可以减少重平衡的延迟
group.initial.rebalance.delay.ms=0
# 请求确认设置,确保数据完整性
request.required.acks=-1
# 默认副本因子,确保高可用性
replication.factor=3
# 最小同步副本数,确保数据不丢失
min.insync.replicas=2
# 禁止不干净的领导者选举
unclean.leader.election.enable=false
EOF
db-52:
tar zxf kafka_2.13-3.2.0.tgz -C /opt/
ln -s /opt/kafka_2.13-3.2.0/ /opt/kafka
mkdir -p /data/kafka/logs
cat > /opt/kafka/config/server.properties << EOF
# 设置每个broker的唯一ID,必须在集群中是唯一的
broker.id=2
# 配置监听地址,确保与服务器IP一致
listeners=PLAINTEXT://10.0.0.52:9092
# 配置网络线程数,根据服务器核心数调整
num.network.threads=3
# 配置I/O线程数,通常设置为处理器的核心数
num.io.threads=8
# Socket发送缓冲区的大小
socket.send.buffer.bytes=102400
# Socket接收缓冲区的大小
socket.receive.buffer.bytes=102400
# 请求的最大字节数,用于防止内存溢出
socket.request.max.bytes=104857600
# 日志文件存储的目录
log.dirs=/data/kafka/logs
# 分区数,每个主题的默认分区数
num.partitions=3
# 每个数据目录的数据恢复线程数
num.recovery.threads.per.data.dir=1
# 偏移量主题的副本因子,应至少等于集群中的节点数减一,以确保高可用
offsets.topic.replication.factor=3
# 事务状态日志的副本因子,应设置为集群节点数以确保事务的持久性
transaction.state.log.replication.factor=3
# 最小同步副本数,设置为2以确保至少有一个副本同步
transaction.state.log.min.isr=2
# 日志保留时间,24小时
log.retention.hours=24
# 单个日志文件的最大大小
log.segment.bytes=1073741824
# 日志保留检查间隔,单位毫秒
log.retention.check.interval.ms=300000
# Zookeeper集群的连接字符串
zookeeper.connect=10.0.0.51:2181,10.0.0.52:2181,10.0.0.53:2181
# Zookeeper连接超时时间,单位毫秒
zookeeper.connection.timeout.ms=6000
# 初始重平衡延迟,设置为0可以减少重平衡的延迟
group.initial.rebalance.delay.ms=0
# 请求确认设置,确保数据完整性
request.required.acks=-1
# 默认副本因子,确保高可用性
replication.factor=3
# 最小同步副本数,确保数据不丢失
min.insync.replicas=2
# 禁止不干净的领导者选举
unclean.leader.election.enable=false
EOF
db-53:
tar zxf kafka_2.13-3.2.0.tgz -C /opt/
ln -s /opt/kafka_2.13-3.2.0/ /opt/kafka
mkdir -p /data/kafka/logs
cat >/opt/kafka/config/server.properties<<EOF
tar zxf kafka_2.13-3.2.0.tgz -C /opt/
ln -s /opt/kafka_2.13-3.2.0/ /opt/kafka
mkdir -p /data/kafka/logs
cat > /opt/kafka/config/server.properties << EOF
# 设置每个broker的唯一ID,必须在集群中是唯一的
broker.id=3
# 配置监听地址,确保与服务器IP一致
listeners=PLAINTEXT://10.0.0.53:9092
# 配置网络线程数,根据服务器核心数调整
num.network.threads=3
# 配置I/O线程数,通常设置为处理器的核心数
num.io.threads=8
# Socket发送缓冲区的大小
socket.send.buffer.bytes=102400
# Socket接收缓冲区的大小
socket.receive.buffer.bytes=102400
# 请求的最大字节数,用于防止内存溢出
socket.request.max.bytes=104857600
# 日志文件存储的目录
log.dirs=/data/kafka/logs
# 分区数,每个主题的默认分区数
num.partitions=3
# 每个数据目录的数据恢复线程数
num.recovery.threads.per.data.dir=1
# 偏移量主题的副本因子,应至少等于集群中的节点数减一,以确保高可用
offsets.topic.replication.factor=3
# 事务状态日志的副本因子,应设置为集群节点数以确保事务的持久性
transaction.state.log.replication.factor=3
# 最小同步副本数,设置为2以确保至少有一个副本同步
transaction.state.log.min.isr=2
# 日志保留时间,24小时
log.retention.hours=24
# 单个日志文件的最大大小
log.segment.bytes=1073741824
# 日志保留检查间隔,单位毫秒
log.retention.check.interval.ms=300000
# Zookeeper集群的连接字符串
zookeeper.connect=10.0.0.51:2181,10.0.0.52:2181,10.0.0.53:2181
# Zookeeper连接超时时间,单位毫秒
zookeeper.connection.timeout.ms=6000
# 初始重平衡延迟,设置为0可以减少重平衡的延迟
group.initial.rebalance.delay.ms=0
# 请求确认设置,确保数据完整性
request.required.acks=-1
# 默认副本因子,确保高可用性
replication.factor=3
# 最小同步副本数,确保数据不丢失
min.insync.replicas=2
# 禁止不干净的领导者选举
unclean.leader.election.enable=false
EOF
启动测试
启动zookeeper
/opt/zookeeper/bin/zkServer.sh start
/opt/zookeeper/bin/zkServer.sh status
前台启动kafka
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
后台启动kafka
/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
检查
jps
systemd配置
zookeeper
cat > /usr/lib/systemd/system/zookeeper.service << EOF
[Unit]
Description=zookeeper service
After=network.target syslog.target remote-fs.target nss-lookup.target
[Service]
Type=forking
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/jdk/bin"
ExecStart=/opt/zookeeper/bin/zkServer.sh start
ExecReload=/opt/zookeeper/bin/zkServer.sh restart
ExecStop=/opt/zookeeper/bin/zkServer.sh stop
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start zookeeper.service
kafka
cat > /usr/lib/systemd/system/kafka.service << EOF
[Unit]
Description=kafka service
After=network.target syslog.target remote-fs.target nss-lookup.target
[Service]
Type=simple
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/jdk/bin"
LimitNOFILE=102400
ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start kafka.service
更新: 2024-10-07 14:35:54