第3章 Elasticsearch集群搭建
本章介绍Elasticsearch集群的概念、部署、扩容和运维管理,帮助实现高可用性、数据冗余和负载均衡。
4.1 集群核心概念
集群特点:
对运维友好:不需要太多java的知识也可以很方便的维护整个集群。
搭建方便:搭建副本非常简单,只需要将新节点加入已有集群即可,会自动同步数据。
自动故障转移:当节点出现故障时,会自动故障转移,将有数据复制到其他正常的节点。
数据分片机制:
主分片: 实际存储的数据,负责读写,粗框的是主分片
副本分片: 主分片的副本,提供读,同步主分片,细框的是副本分片
主分片负责写入操作,副本分片提供数据备份和读取负载分担,同一索引的主分片和副本分片不会在同一节点上。
副本作用:
主分片的备份,副本数量可以自定义
副本提供数据容错、读取性能分担和高可用性保障。
默认配置:
7.X版本之前默认规则: 1副本,5分片
7.x版本之后默认规则: 1副本,1分片
7.x后减少默认分片数避免过度分片,单分片在小数据量时性能更好。
节点类型:
主节点: 负责调度数据分配到哪个节点
数据节点: 实际负责处理数据的节点
默认: 主节点也是工作节点
集群健康状态:
绿色: 所有数据都完整,且副本数满足
黄色: 所有数据都完整,但是副本数不满足
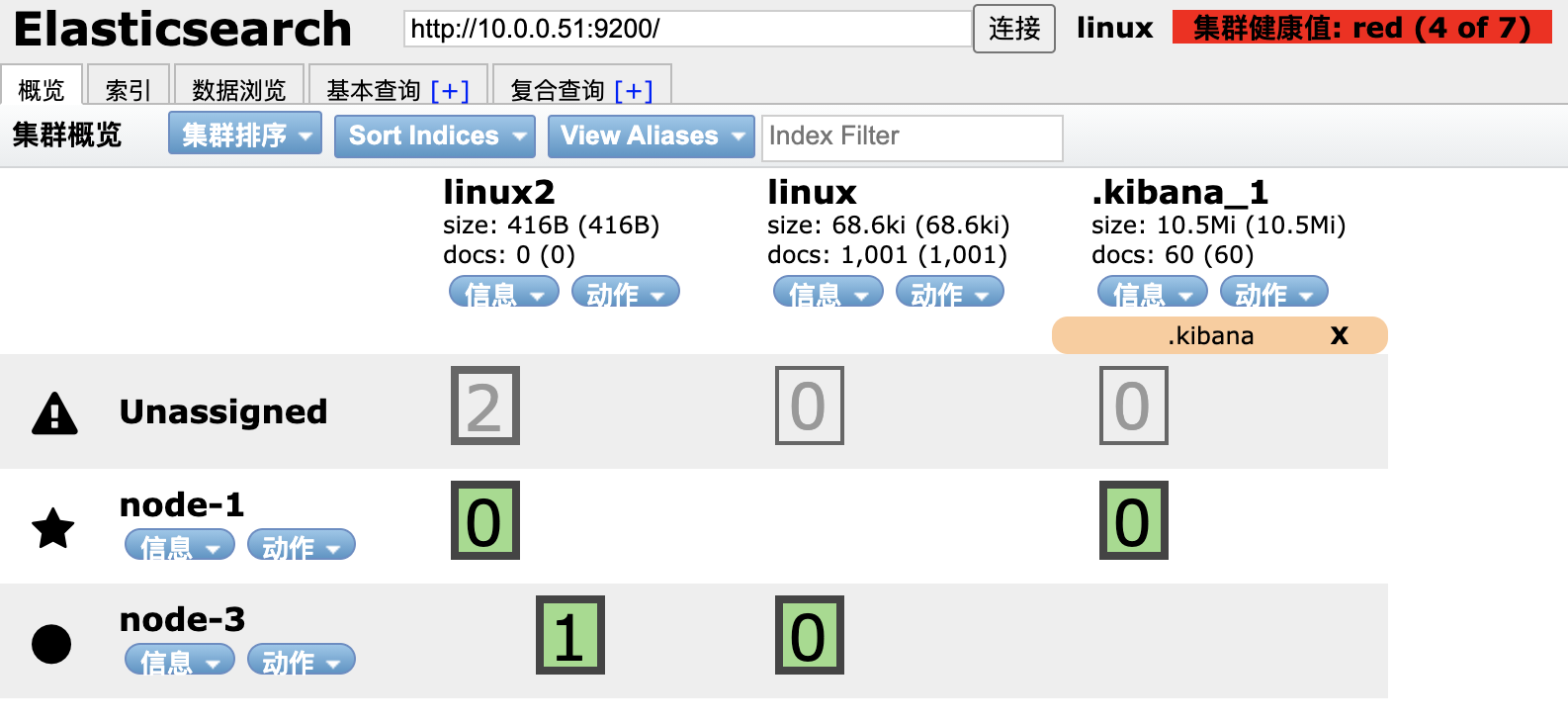
红色: 一个或多个索引数据不完整
4.2 集群部署实战
部署准备:
最好是使用干净的环境部署集群,如果以前有单节点的数据,最好备份出来,然后再清空集群数据。
⚠️ 重要操作
清理旧数据前务必备份!
systemctl stop elasticsearch.service
rm -rf /var/lib/elasticsearch/*
软件安装:
# 7.x版本之后不需要单独的安装JDK,软件包自带了JDK
rpm -ivh elasticsearch-7.9.1-x86_64.rpm
# 配置内存锁定
systemctl edit elasticsearch.service
[Service]
LimitMEMLOCK=infinity
Node1配置文件:
cat > /etc/elasticsearch/elasticsearch.yml <<EOF
cluster.name: luffy_linux
node.name: node-1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 127.0.0.1,10.0.0.51
http.port: 9200
discovery.seed_hosts: ["10.0.0.51","10.0.0.52"]
cluster.initial_master_nodes: ["10.0.0.51"]
EOF
Node2配置文件:
cat > /etc/elasticsearch/elasticsearch.yml <<EOF
cluster.name: luffy_linux
node.name: node-2
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 127.0.0.1,10.0.0.52
http.port: 9200
discovery.seed_hosts: ["10.0.0.51","10.0.0.52"]
cluster.initial_master_nodes: ["10.0.0.51"]
EOF
关键配置说明:
在 Elasticsearch 集群配置中,cluster.initial_master_nodes 是一个非常重要的参数,它用于指定在集群首次启动时,哪些节点有资格被选为主节点(Master Node)。这个参数只在集群首次启动时生效,后续的集群启动或节点加入时不再需要。
Elasticsearch 集群需要一个主节点来协调集群状态(如索引创建、分片分配等)。在集群首次启动时,Elasticsearch 需要确定哪些节点有资格成为主节点。如果没有明确指定,可能会导致集群无法正确启动或出现脑裂(Split Brain)问题。
启动和验证:
# 启动服务
systemctl daemon-reload
systemctl restart elasticsearch
# 查看日志
tail -f /var/log/elasticsearch/luffy_linux.log
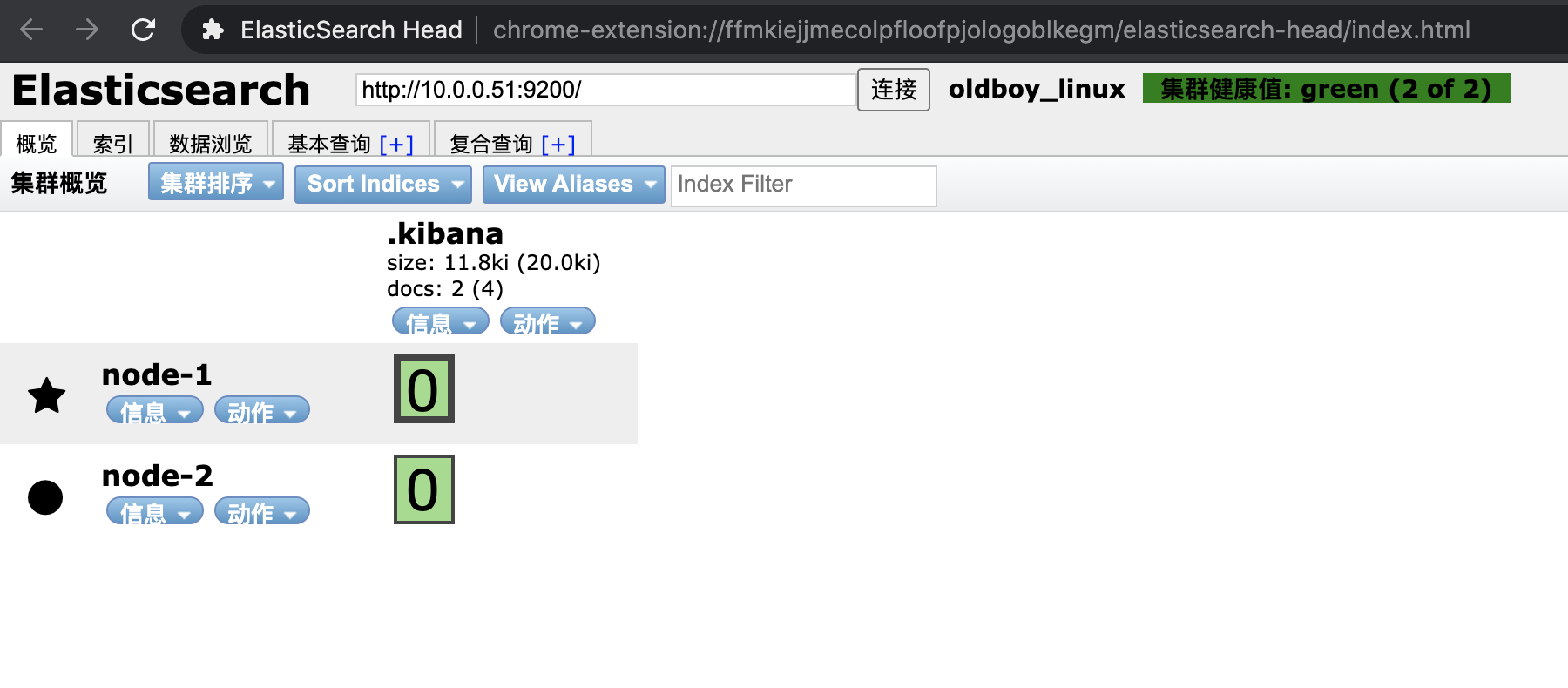
4.3 集群扩容管理
新节点安装:
# 7.0版本之后不需要单独安装JDK
rpm -ivh elasticsearch-7.9.1-x86_64.rpm
# 配置内存锁定
systemctl edit elasticsearch.service
[Service]
LimitMEMLOCK=infinity
Node3配置:
cat > /etc/elasticsearch/elasticsearch.yml <<EOF
cluster.name: oldboy_linux
node.name: node-3
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 127.0.0.1,10.0.0.53
http.port: 9200
discovery.seed_hosts: ["10.0.0.51","10.0.0.53"]
cluster.initial_master_nodes: ["10.0.0.51"]
EOF
扩容要点:
对于新添加的节点来说:
只需要知道集群内任意一个节点的IP和他自己本身的IP即可
discovery.seed_hosts: ["10.0.0.51","10.0.0.53"]
对于以前的节点来说:
什么都不需要更改
分片状态监控:
紫色: 正在迁移
黄色: 正在复制
绿色: 正常
新节点加入后会触发分片重新分配,数据迁移过程中分片状态会变化,最终达到绿色健康状态。
故障转移测试场景:
1.停掉主节点,观察集群是否正常
2.停掉主节点,是否还会选举出新的主节点
3.停掉主节点,数据分片的分布会不会发生变化,分片状态会不会发生变化
4.停掉主节点,然后在持续的写入数据,等节点恢复之后,会如何处理落后的数据
5.3个节点的Elasticsearch集群,极限情况下最多允许坏几台?
6.主节点故障,集群健康状态发生什么变化?
故障转移结论:
1.如果主节点坏掉了,会从活着的数据节点中选出一台新的主节点
2.如果主分片坏掉了,副本分片会升级为主分片
3.如果副本数不满足,会尝试在其他的节点上重新复制一份数据
4.修复上线只需要正常启动故障的节点即会自动加入到集群里,并且自动同步数据
5.7.x版本之后则必须至少2个节点存活集群才能正常工作
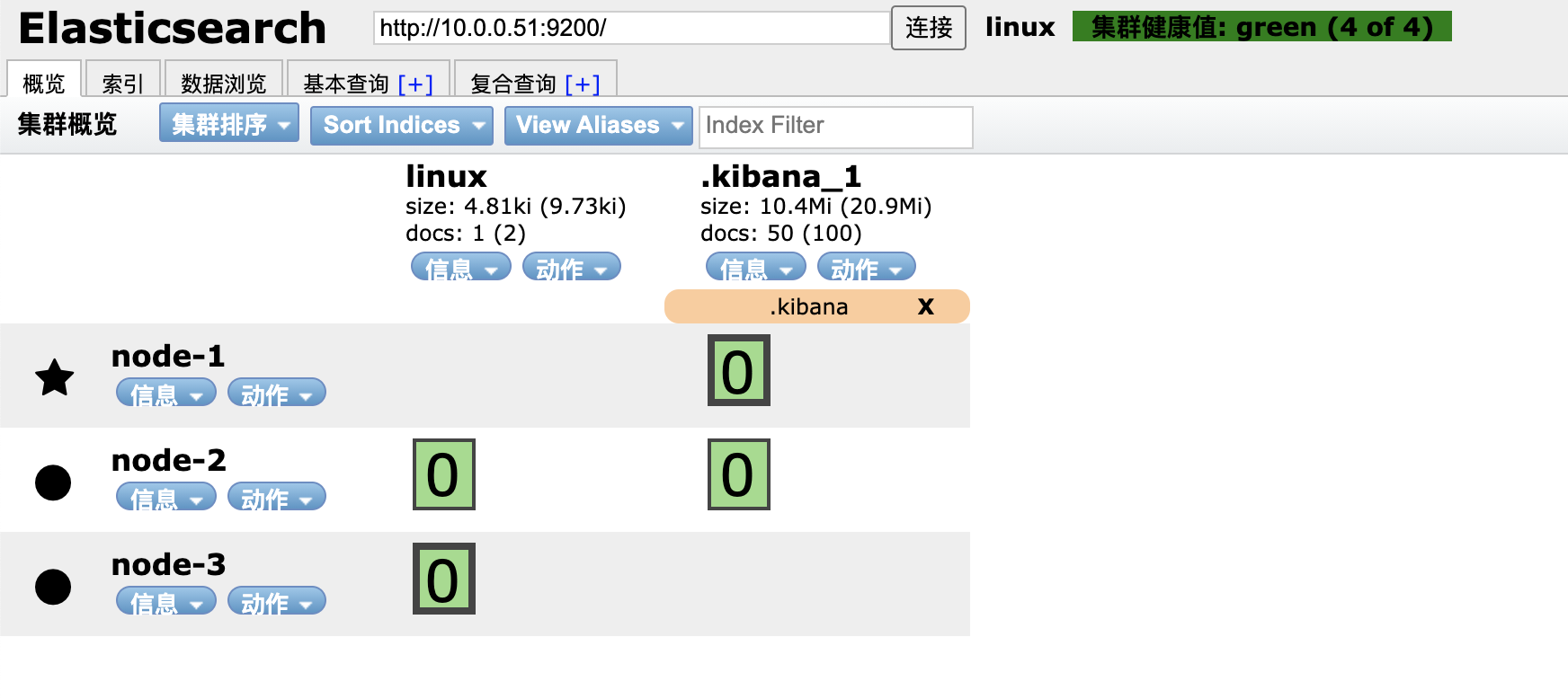
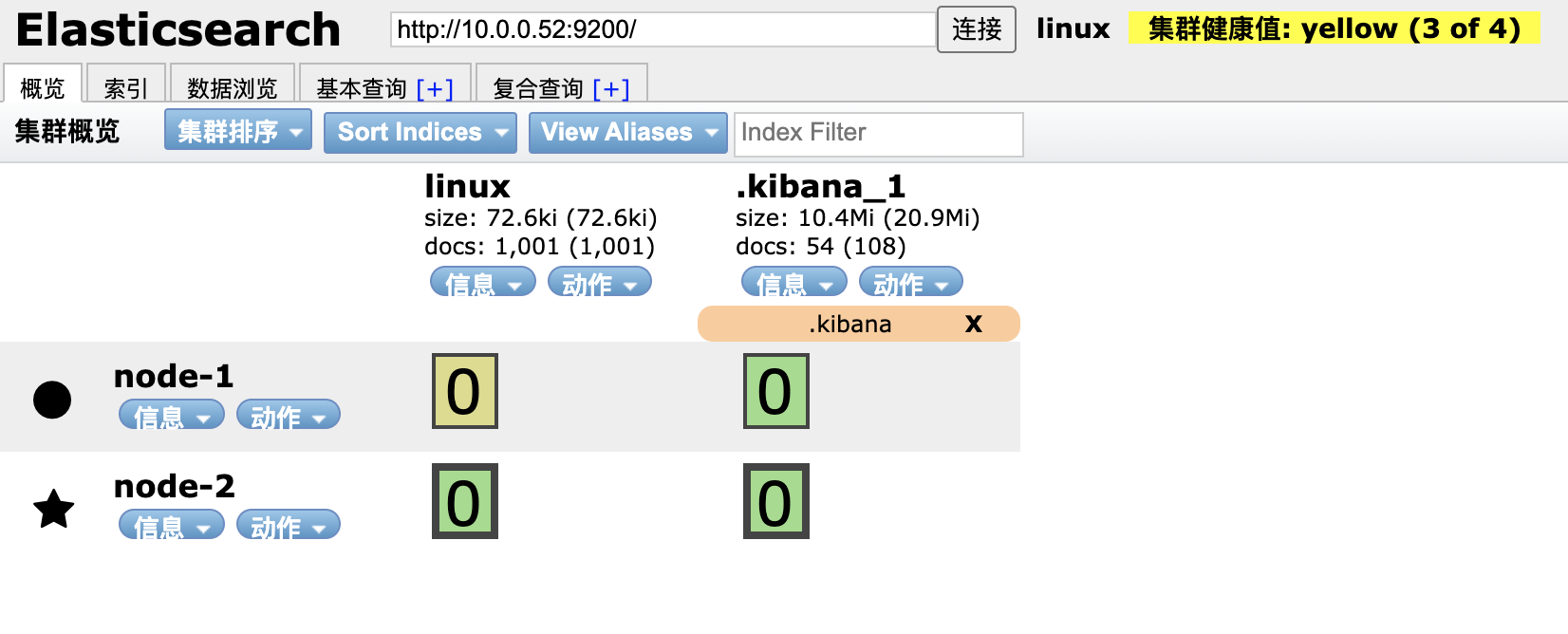
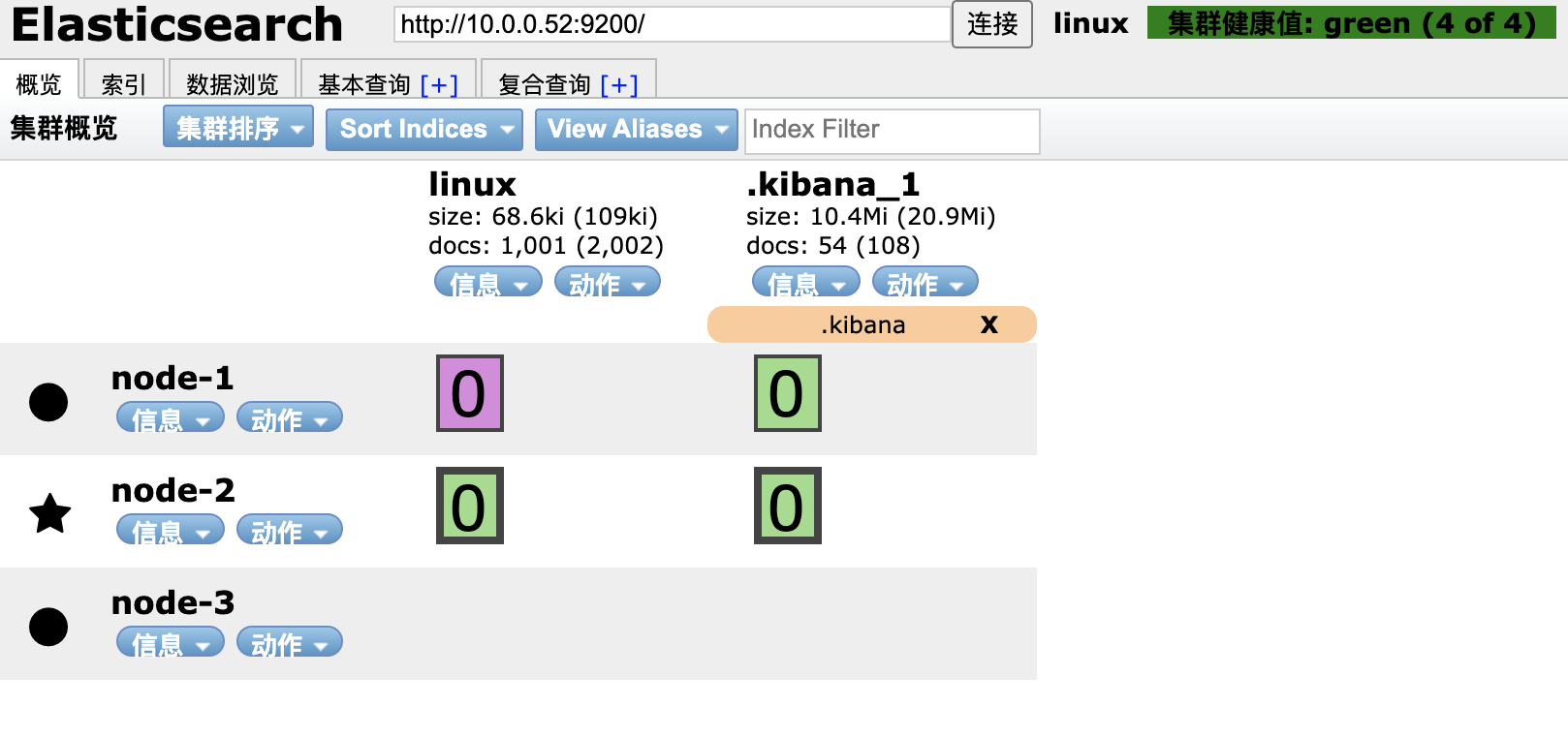
4.4 集群运维实践
索引副本管理:
索引一旦建立完成,分片数就不可以修改了
但是副本数可以随时修改
# 创建索引时自定义副本和分片
PUT /linux2/
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
}
}
# 修改单个索引的副本数
PUT /linux2/_settings/
{
"settings": {
"number_of_replicas": 2
}
}
# 修改所有的索引的副本数
PUT /_all/_settings/
{
"settings": {
"number_of_replicas": 0
}
}
生产环境配置建议:
2个节点: 默认就可以
3个节点: 重要的数据,2副本 不重要的默认
日志收集: 1副本3分片
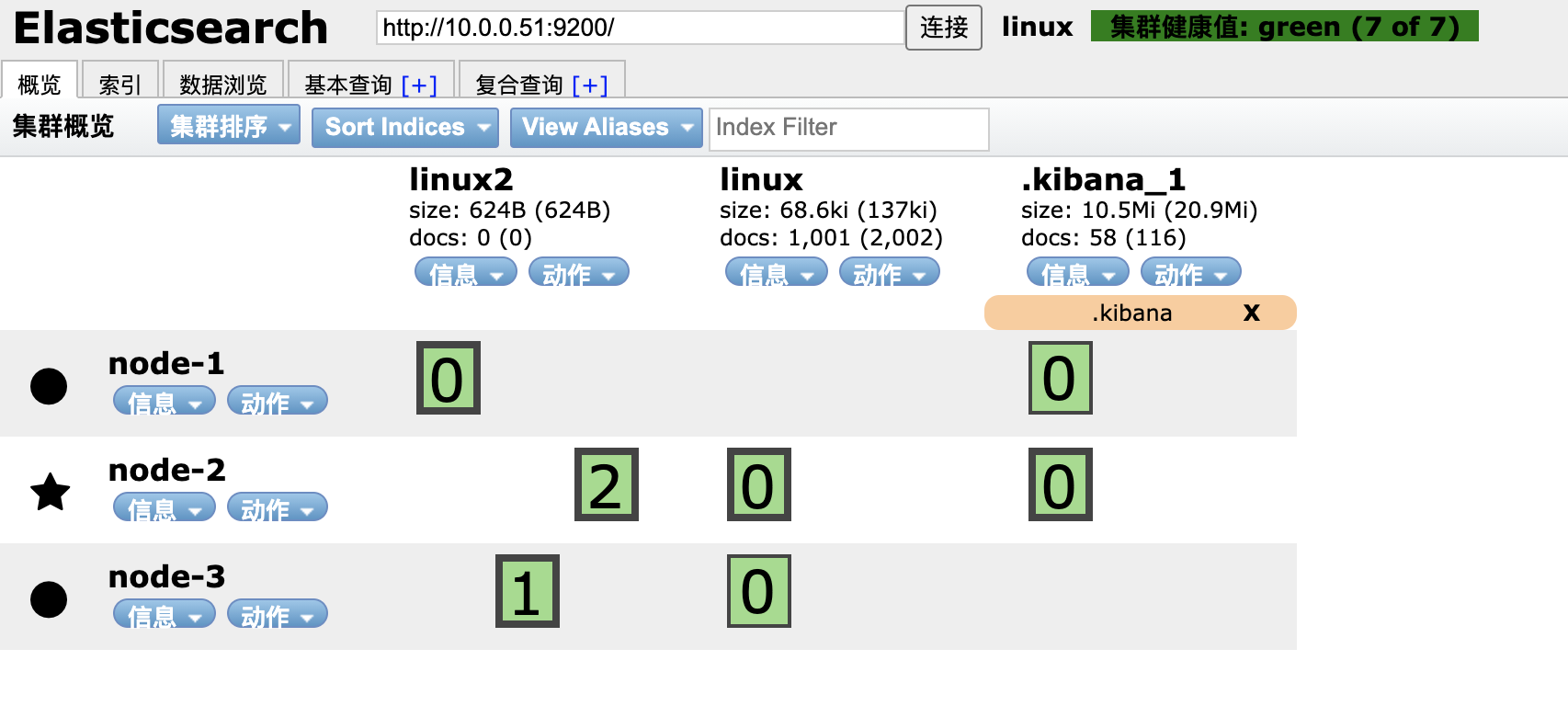
运维注意事项:
1.插入和读取数据在任意节点都可以执行,效果一样
2.es-head可以连接集群内任一台服务
3.主节点负责读写
如果主分片所在的节点坏掉了,副本分片会升为主分片
4.主节点负责调度
如果主节点坏掉了,数据节点会自动升为主节点
5.通讯端口
默认会有2个通讯端口:9200和9300
9300并没有在配置文件里配置过
如果开启了防火墙并且没有放开9300端口,那么集群通讯就会失败
🚨 生产环境重要提醒
生产环境运维要点:
- 定期检查集群健康状态
- 确保分片均匀分布在各节点
- 监控CPU、内存、磁盘使用率
- 确保9200和9300端口通畅
⚠️ 故障排除指南
常见问题诊断:
- 集群状态异常 - 检查节点网络连通性、配置文件一致性、查看日志错误
- 分片未分配 - 检查磁盘空间、验证副本配置、手动重新分配分片
- 节点无法加入 - 验证cluster.name一致性、检查discovery.seed_hosts配置、确认防火墙端口
应急处理命令:
# 查看未分配分片
GET /_cat/shards?v&h=index,shard,prirep,state,unassigned.reason
# 手动分配分片
POST /_cluster/reroute
{
"commands": [
{
"allocate_empty_primary": {
"index": "my-index",
"shard": 0,
"node": "node-1",
"accept_data_loss": true
}
}
]
}
本章小结
通过本章学习,掌握了集群核心概念、部署技能、扩容管理和运维实战经验。集群部署是Elasticsearch生产应用的基础,合理的集群架构和运维策略是保证服务稳定性的关键。
📝 更新时间: 2025-01-26
🎯 适用版本: Elasticsearch 7.x/8.x
📚 难度等级: 中级进阶