第4章 MySQL单表查询
SQL语言基础
1. SQL介绍与分类
SQL定义
SQL(Structured Query Language)是关系型数据库的标准查询语言,用于管理和操作数据库。
SQL分类
DDL(数据定义语言)
- CREATE:创建数据库、表、视图等对象
- ALTER:修改数据库对象结构
- DROP:删除数据库对象
- TRUNCATE:清空表数据
DML(数据操作语言)
- SELECT:查询数据
- INSERT:插入数据
- UPDATE:更新数据
- DELETE:删除数据
DCL(数据控制语言)
- GRANT:授予权限
- REVOKE:回收权限
2. 数据库对象与属性
字符集
常用字符集:
utf8:最大支持3字节,不支持emojiutf8mb4:最大支持4字节,支持emoji(推荐)
MySQL 8.0之前默认字符集为latin1,8.0之后为utf8mb4。建议统一使用utf8mb4。
列数据类型
数字类型
tinyint:1字节,范围-128到127(或无符号0-255)int:4字节,范围约-21亿到+21亿bigint:8字节,支持20位数decimal(m,n):精确小数,m为总位数,n为小数位数
字符串类型
char(N):定长字符串,最大255字符,空间固定varchar(M):变长字符串,最大65535字符,额外1-2字节存储长度enum:枚举类型,从预定义值中选择
时间类型
DATETIME:8字节,范围1000-01-01至9999-12-31TIMESTAMP:4字节,范围1970-01-01至2038-01-19,受时区影响
列约束
- PRIMARY KEY:主键,非空+唯一,每表只能一个,建议使用自增数字列
- NOT NULL:非空约束,必须录入值,有利于索引应用
- UNIQUE KEY:唯一约束,不允许重复值
- UNSIGNED:无符号,用于数字列
其他属性
表属性:
engine:存储引擎,默认InnoDBcharset:字符集,建议utf8mb4comment:表注释
列属性:
default:默认值auto_increment:自增长comment:列注释
DDL数据定义语言
1. 库的定义与管理
库定义规范
- 库名不能数字开头
- 库名要与业务相关
- 库名使用小写字符(多平台兼容)
- 显示指定字符集utf8mb4
- 生产环境禁用drop database权限
库操作语句
-- 创建库
CREATE DATABASE oldya CHARSET utf8mb4;
CREATE DATABASE luffy;
-- 查看库
SHOW DATABASES;
SHOW CREATE DATABASE luffy;
-- 修改库字符集
ALTER DATABASE oldya CHARSET utf8mb4;
-- 删除库
DROP DATABASE oldya;
字符集设置:
-- 查看字符集变量
SHOW VARIABLES LIKE '%char%';
-- 设置客户端字符集
SET NAMES utf8mb4;
配置文件默认字符集:
[mysqld]
character_set_server=utf8mb4;
2. 表的定义与管理
建表规范
表名规范:
- 不能数字开头,不超过18字符
- 与业务相关,使用小写
- 不使用关键字
表结构规范:
- 存储引擎使用InnoDB
- 字符集使用utf8mb4
- 每个表必须有主键
- 每个列设置NOT NULL和注释
- 选择合适的数据类型
提示
SQL审核工具推荐:Yearning、Inception。生产环境修改表结构建议使用pt-osc或gh-ost工具。
创建表
主键概念:主键(PRIMARY KEY)是唯一标识表中每一行的列或列组合,强制表的实体完整性。
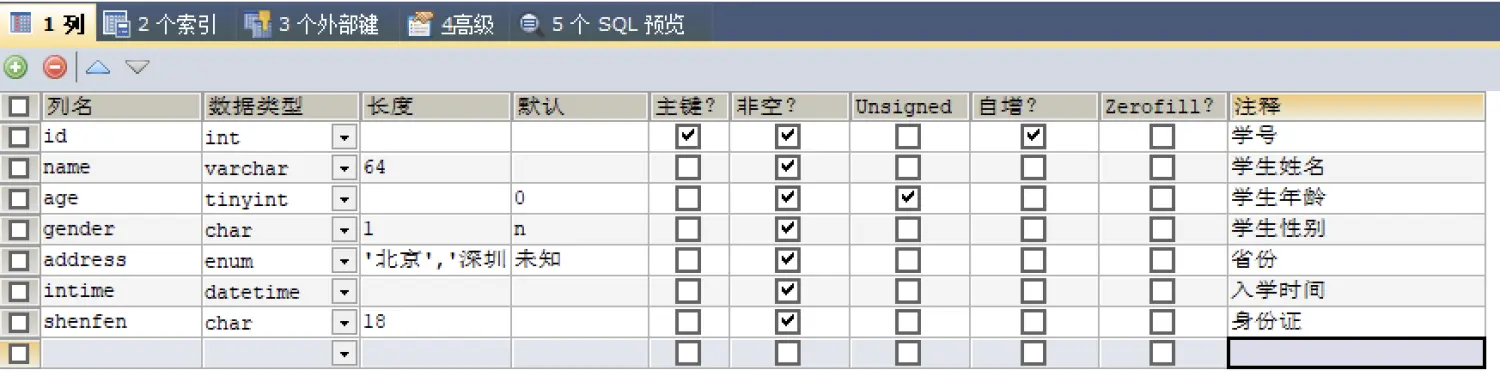
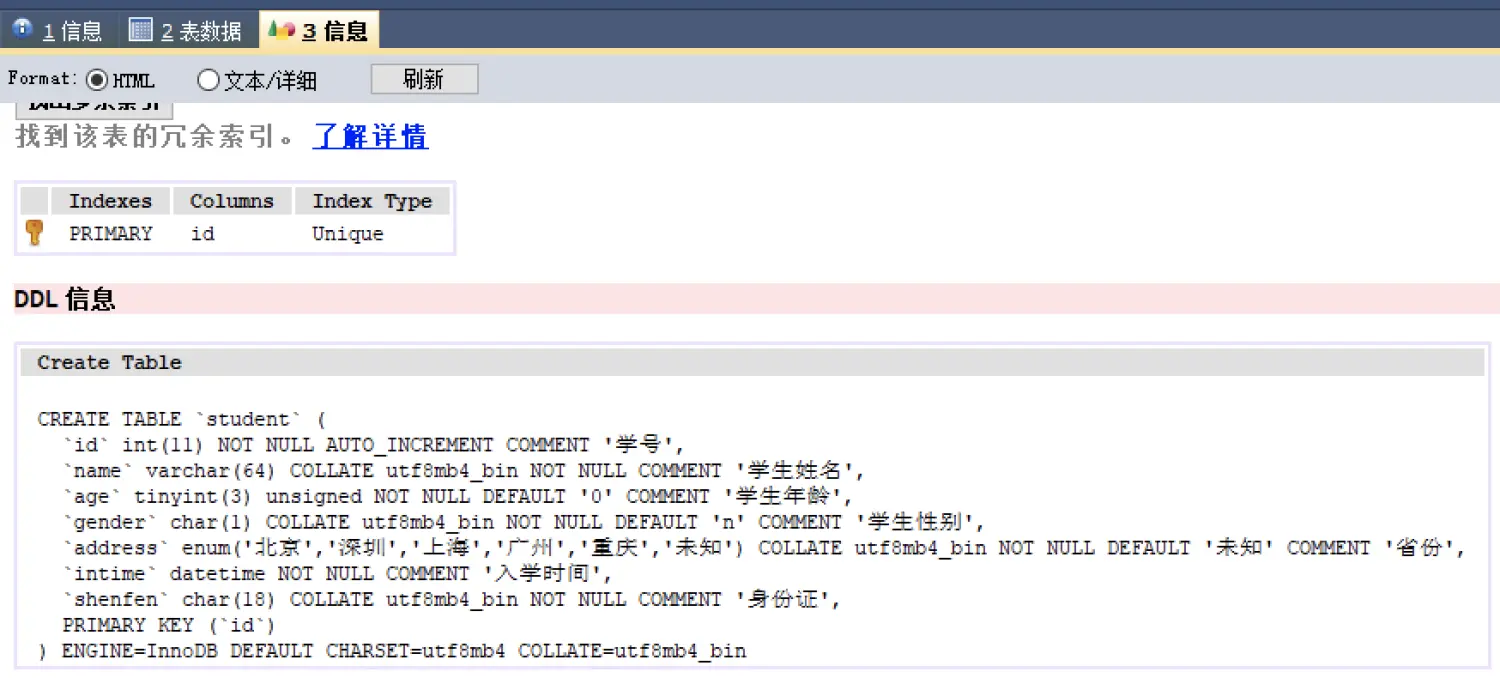
建表示例:
CREATE DATABASE school CHARSET utf8mb4;
USE school;
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '学号',
`name` varchar(64) COLLATE utf8mb4_bin NOT NULL COMMENT '学生姓名',
`age` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '学生年龄',
`gender` char(1) COLLATE utf8mb4_bin NOT NULL DEFAULT 'n' COMMENT '学生性别',
`address` enum('北京','深圳','上海','广州','重庆','未知') COLLATE utf8mb4_bin NOT NULL DEFAULT '未知' COMMENT '省份',
`intime` datetime NOT NULL COMMENT '入学时间',
`shenfen` char(18) COLLATE utf8mb4_bin NOT NULL COMMENT '身份证',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
查看表信息
-- 查看所有表
USE school;
SHOW TABLES;
-- 查看建表语句
SHOW CREATE TABLE student;
-- 查看表结构
DESC student;
-- 复制表结构
CREATE TABLE stu LIKE student;
修改表结构
添加列(推荐在末尾添加):
ALTER TABLE student
ADD COLUMN telnum CHAR(11) NOT NULL UNIQUE KEY DEFAULT '0' COMMENT '手机号';
-- 不推荐:在指定位置添加
alter table student add column a CHAR(11) after gender; -- 在gender后
alter table student add column b CHAR(11) first; -- 在第一列
注意
生产环境删除列操作极其危险,需谨慎操作!
ALTER TABLE student DROP COLUMN telnum;
修改表属性
-- 修改表名
ALTER TABLE student RENAME TO st;
-- 修改存储引擎
ALTER TABLE t1 ENGINE=INNODB;
-- 修改字符集
ALTER TABLE t2 CHARSET=utf8mb4;
修改列属性
-- 修改列名(使用CHANGE)
ALTER TABLE st CHANGE shenfen cardnum CHAR(18) NOT NULL DEFAULT '0' COMMENT '身份证';
-- 修改数据类型(使用MODIFY)
ALTER TABLE st MODIFY cardnum CHAR(20) NOT NULL DEFAULT '1' COMMENT '身份证';
-- 删除表
DROP TABLE st;
DML数据操作语言
1. 数据插入(INSERT)
建表准备
USE school;
CREATE TABLE `st` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '学号',
`name` varchar(64) COLLATE utf8mb4_bin NOT NULL COMMENT '学生姓名',
`age` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '学生年龄',
`gender` char(1) COLLATE utf8mb4_bin NOT NULL DEFAULT 'n' COMMENT '学生性别',
`address` enum('北京','深圳','上海','广州','重庆','未知') COLLATE utf8mb4_bin NOT NULL DEFAULT '未知' COMMENT '省份',
`intime` datetime NOT NULL COMMENT '入学时间',
`cardnum` char(18) COLLATE utf8mb4_bin NOT NULL COMMENT '身份证',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
INSERT语法示例
标准语法(指定列名):
INSERT INTO st(id,NAME,age,gender,address,intime,cardnum)
VALUES(1,'张三',18,'m','北京','2020-09-06','666666');
部分列插入:
INSERT INTO st(NAME,intime)
VALUES('李四',NOW());
省略列名(需按表结构顺序提供所有值):
INSERT INTO st
VALUES(5,'张三',18,'m','北京','2020-04-27','666666');
提示
建议使用标准语法明确指定列名,提高代码可读性和维护性。
2. 数据更新(UPDATE)
-- 更新单列
UPDATE st SET NAME='张六' WHERE id=3;
-- 更新多列
UPDATE st SET name='张七', age=21 WHERE id=4;
注意
更新操作必须加WHERE条件,否则会更新所有行!
3. 数据删除(DELETE/TRUNCATE)
物理删除
-- 删除指定行
DELETE FROM st WHERE id=3;
伪删除(推荐方案)
在生产环境中,建议使用伪删除策略保护数据安全:
-- 1) 添加状态列
ALTER TABLE st ADD COLUMN state TINYINT NOT NULL DEFAULT 1 COMMENT '状态:1存在,0删除';
-- 2) 使用UPDATE替代DELETE
UPDATE st SET state=0 WHERE id=4;
-- 3) 查询时过滤已删除数据
SELECT * FROM st WHERE state=1;
删除操作对比
| 操作 | 作用 | 特点 |
|---|---|---|
| DROP TABLE | 删除表结构和数据 | 物理删除,释放空间,删除元数据 |
| TRUNCATE TABLE | 清空表数据 | 物理删除,释放空间,保留表结构 |
| DELETE FROM | 删除数据行 | 逻辑删除,不立即释放空间,可能产生碎片 |
危险
生产环境应限制DROP和TRUNCATE权限,优先使用伪删除策略。
DQL数据查询语言(单表)
1. SELECT基础查询
业务表结构分析
在编写查询前,先了解表结构是关键步骤:
-- 查看表结构
DESC city;
-- 查看部分数据
SELECT * FROM city WHERE id < 10;
city表字段说明:
id:主键,自增数字name:城市名称countrycode:国家代码(三位字母)district:行政区域(省/州/县)population:城市人口
查询语法结构
SELECT 列名
FROM 表名
WHERE 条件
GROUP BY 分组列
HAVING 分组后条件
ORDER BY 排序列
LIMIT 返回行数
系统信息查询
服务器参数查询:
SELECT @@port, @@server_id, @@basedir, @@datadir;
SHOW VARIABLES LIKE '%innodb%';
内置函数使用:
SELECT DATABASE(), NOW(), USER();
SELECT CONCAT('用户: ', user, '@', host) FROM mysql.user;
基本查询示例
-- 查询所有列
SELECT * FROM city;
-- 查询指定列
SELECT name, population FROM city;
-- 使用完整表名
SELECT id, name FROM world.city;
2. WHERE条件过滤
比较运算符
-- 等于条件
SELECT * FROM city WHERE countrycode = 'CHN';
-- 数值比较
SELECT * FROM city WHERE population < 100;
SELECT * FROM city WHERE population > 5000000;
逻辑运算符
-- AND组合条件
SELECT * FROM city WHERE countrycode='CHN' AND population > 5000000;
-- OR条件
SELECT * FROM city WHERE countrycode='CHN' OR countrycode='USA';
-- IN操作符(替代多个OR)
SELECT * FROM city WHERE countrycode IN ('CHN','USA');
范围查询
-- 使用AND组合
SELECT * FROM city WHERE population >= 1000000 AND population <= 2000000;
-- 使用BETWEEN
SELECT * FROM city WHERE population BETWEEN 1000000 AND 2000000;
模糊匹配
-- LIKE操作符
SELECT * FROM city WHERE name LIKE 'qing%'; -- qing开头
SELECT * FROM city WHERE name LIKE '%jing'; -- jing结尾
SELECT * FROM city WHERE name LIKE '%jing%'; -- 包含jing
3. GROUP BY分组聚合
聚合函数
| 函数 | 功能 |
|---|---|
| COUNT() | 统计数量 |
| SUM() | 求和 |
| AVG() | 平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| GROUP_CONCAT() | 列转行 |
分组原理
GROUP BY执行过程:
- 按分组条件排序
- 分组列去重
- 聚合函数计算各组结果
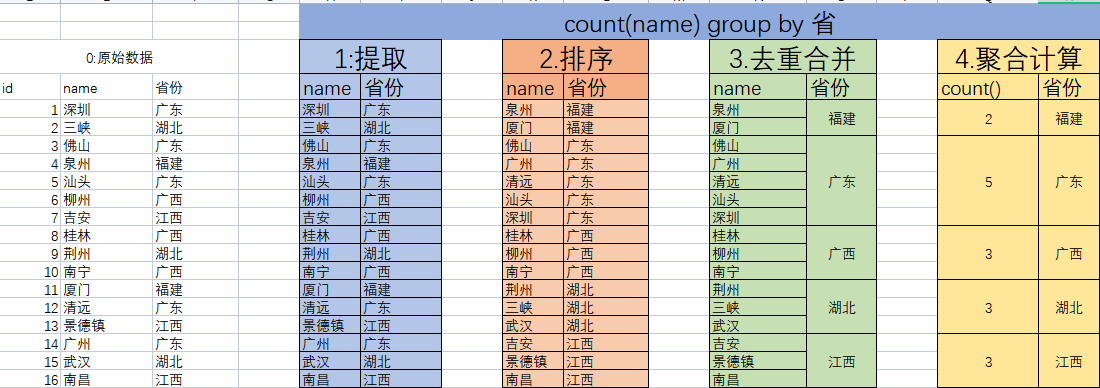
聚合查询示例
基础统计:
-- 统计总行数
SELECT COUNT(*) FROM city;
-- 统计中国城市数量
SELECT COUNT(*) FROM city WHERE countrycode='CHN';
-- 统计中国总人口
SELECT SUM(population) FROM city WHERE countrycode='CHN';
分组统计:
-- 各国城市数量
SELECT countrycode, COUNT(name) FROM city GROUP BY countrycode;
-- 各国总人口
SELECT countrycode, SUM(population) FROM city GROUP BY countrycode;
-- 中国各省城市统计
SELECT district, COUNT(name), GROUP_CONCAT(name)
FROM city
WHERE countrycode='CHN'
GROUP BY district;
HAVING过滤分组结果
HAVING用于过滤GROUP BY后的分组结果:
-- 显示总人口超过1亿的国家
SELECT countrycode, SUM(population)
FROM city
GROUP BY countrycode
HAVING SUM(population) > 100000000;
提示
WHERE过滤原始数据行,HAVING过滤分组后的结果。WHERE不能使用聚合函数,HAVING可以。
4. ORDER BY排序与LIMIT分页
排序查询
-- 默认升序排序
SELECT * FROM city ORDER BY population;
-- 降序排序
SELECT * FROM city WHERE countrycode='CHN' ORDER BY population DESC;
-- 多条件排序
SELECT countrycode, SUM(population) AS total_pop
FROM city
GROUP BY countrycode
HAVING total_pop > 50000000
ORDER BY total_pop DESC;
分页查询
-- 查询前10条
SELECT * FROM city
WHERE countrycode = 'CHN'
ORDER BY population DESC
LIMIT 10;
-- 查询第6-10条(跳过5条,显示5条)
SELECT * FROM city
WHERE countrycode = 'CHN'
ORDER BY population DESC
LIMIT 5, 5;
-- 另一种语法
SELECT * FROM city
WHERE countrycode = 'CHN'
ORDER BY population DESC
LIMIT 5 OFFSET 5;
SQL执行顺序
语法顺序:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT ...
执行顺序:
- FROM - 确定数据源
- WHERE - 过滤行
- GROUP BY - 分组
- SELECT - 选择列和聚合计算
- HAVING - 过滤分组
- ORDER BY - 排序
- LIMIT - 限制行数
练习题参考
-- 1. 查询中国人口超过500万的城市
SELECT * FROM city WHERE countrycode='CHN' AND population > 5000000;
-- 2. 统计每个国家城市数量,只显示超过100个城市的国家,按数量降序,取前3
SELECT countrycode, COUNT(*) AS city_count
FROM city
GROUP BY countrycode
HAVING city_count > 100
ORDER BY city_count DESC
LIMIT 3;
-- 3. 查询中国各省城市数量和城市列表
SELECT district, COUNT(*) AS count, GROUP_CONCAT(name) AS cities
FROM city
WHERE countrycode='CHN'
GROUP BY district
ORDER BY count DESC;
更新: 2024-07-12 08:42:09